Beyond Comparing Image Pairs: Setwise Active Learning for Relative Attributes
Lucy Liang and Kristen Grauman
The University of Texas at Austin
Abstract
It is useful to automatically compare images based on their visual properties?to predict which image is brighter, more feminine, more blurry, etc. However, comparative models are inherently more costly to train than their classification counterparts. Manually labeling all pairwise comparisons is intractable, so which pairs should a human supervisor compare? We explore active learning strategies for training relative attribute ranking functions, with the goal of requesting human comparisons only where they are most informative. We introduce a novel criterion that requests a partial ordering for a set of examples that minimizes the total rank margin in attribute space, subject to a visual diversity constraint. The setwise criterion helps amortize effort by identifying mutually informative comparisons, and the diversity requirement safeguards against requests a human viewer will find ambiguous. We develop an efficient strategy to search for sets that meet this criterion. On three challenging datasets and experiments with ?live? online annotators, the proposed method outperforms both traditional passive learning as well as existing active rank learning methods.
Introduction
While vision research has long focused on categorizing visual entities (e.g., recognizing objects in images, or activities in video), there is increasing interest in comparing them. Training a classifier requires ground truth labels that hard-assign each instance to a category, and there are many existing category-labeled datasets and tools that make labeling efficient (e.g., ImageNet, Hollywood videos, etc.). In contrast, training a ranking function requires ground truth comparisons that relate one instance to another (e.g., person A is smiling more than person B; image X is more relevant than image Y), and thus far only modest amounts of comparative annotations are available.

Active learning for image ranking presents three distinct technical challenges:
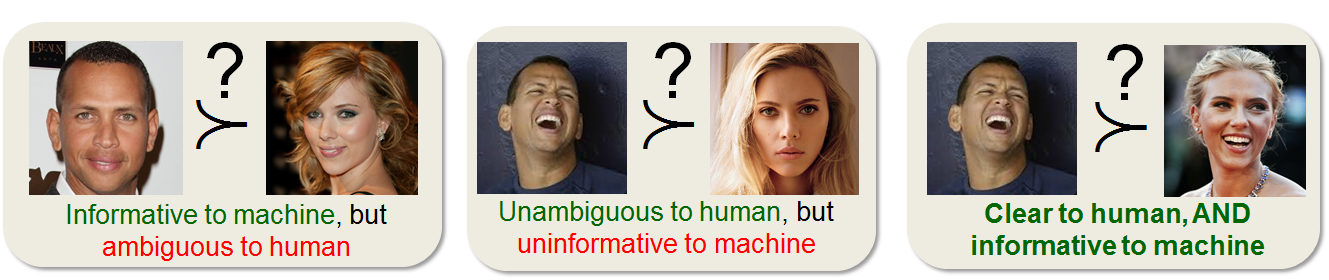
- Fine-grained comparisons can be ambiguous not only to the system but also to the human labeler due to visual similarity.
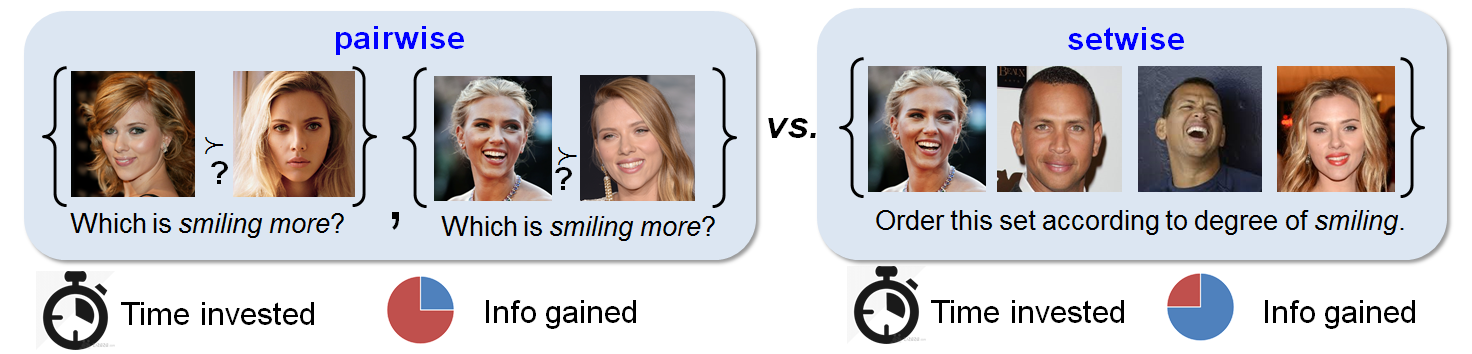
- Pairwise comparisons provide only one bit of training information ? that is, which image has more property than the other, whereas setwise comparisons helps amortize effort by identifying mutually informative comparisons.
- The quadratic number of possible comparisons poses a scalability challenge.
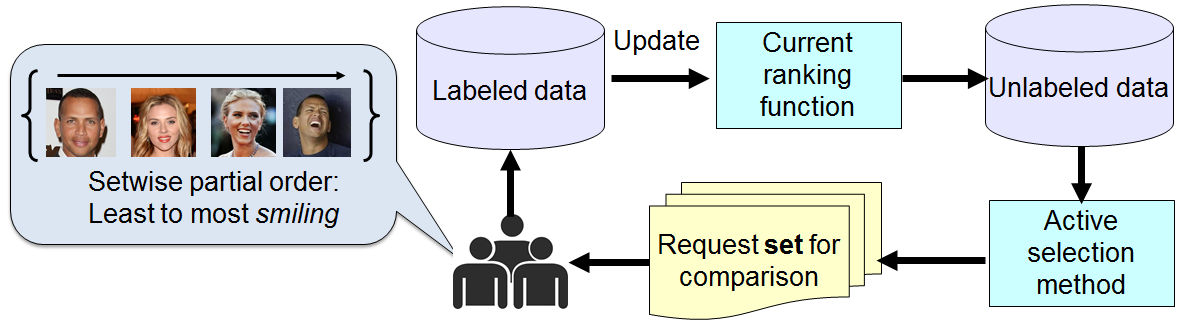
We start with a pairwise margin-based criterion for ranking functions that selects pairs with high uncertainty. Then, we consider a setwise extension~\cite{yu-kdd2005} that requests a partial order on multiple examples at once. Finally, we introduce a novel setwise criterion that both amortizes human perceptual effort and promotes diversity among selected images, thereby avoiding uninformative comparisons that may be too close for even humans to reliably distinguish. See Figure~\ref{fig:concept}. In particular, our formulation seeks a set of examples that minimizes the mutual rank margin in attribute space, subject to a visual diversity constraint in the original image feature space. We show how to efficiently search for batches that meet this criterion. %%% By exploiting the 1D ordering inherent in attribute ranks, we can incrementally adjust candidate batches, yielding an expected run-time that is linear in the number of unlabeled images (not pairs).
Hence, our goal is to select a modest amount image samples that are ambiguous for the machine but not for the human.
Approach
- From pool of unlabeled visual data, request a set of image samples that is both ambiguous/informative for the system and visually diverse for human annotator to rank.
- Human provides informative labels.
- System updates current ranking function with the new information and selects a new set of comparisons.
Background: Learning to Rank
Given ordered image pairs 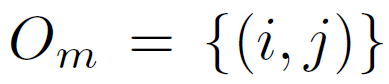 and unordered pairs
and unordered pairs 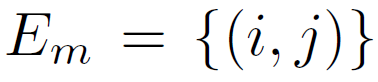 such that
such that 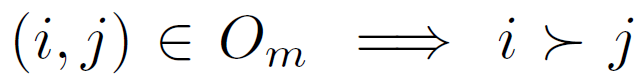 (image i has stronger presence of attribute m than image j) and (the images have equivalent presence of attribute m),
(image i has stronger presence of attribute m than image j) and (the images have equivalent presence of attribute m),
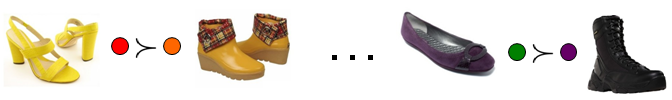
 learn a ranking function
learn a ranking function 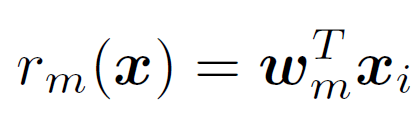 such that as many of the following constraints are satisfied as possible:
such that as many of the following constraints are satisfied as possible:
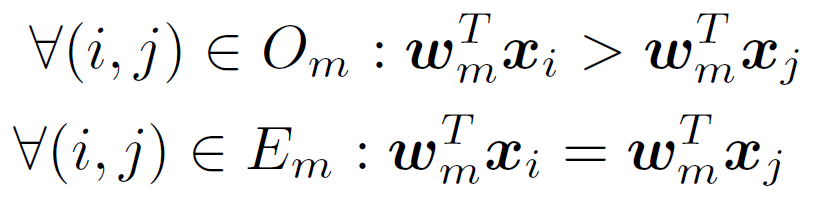
For more on training ranking functions, see: T. Joachims, Optimizing Search Engines Using Clickthrough Data, Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (KDD), ACM, 2002.
Using the derived ranking function, we can project the feature descriptors on to a 1-D ordering. The rank margin is the distance between two consecutive data pairs.
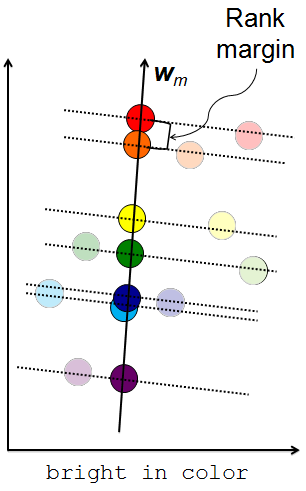
Diverse Setwise Low Margin Active Selection Strategy
Our idea:
- Select comparisons that minimizes the rank margin. These are images whose rankings are most uncertain for the machine and will therefore provide the most information once labeled.
- Select comparisons that are visually diverse by using a clustering-based objective. Visual diversity safeguards against human ambiguity towards images that are "too" similarand increases the likelihood of the images receiving different, meaningful rankings.
- Select sets of images as opposed to pairs of images. Setwise comparisons ammortizes annotation effort across mutually informative pairs within the set.
To capture diversity, we first cluster all the image descriptors (GIST, color) in feature space. This establishes the primary modes among the unlabeled examples. Let 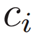 denote the cluster to which image $i$ belongs. Our selection objective is:
denote the cluster to which image $i$ belongs. Our selection objective is:
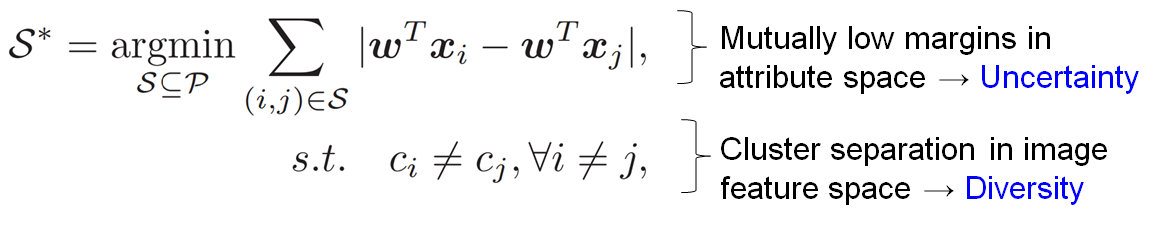
To form the clusters, we use K-means. For more discussion on choosing k, see our supplementary material.
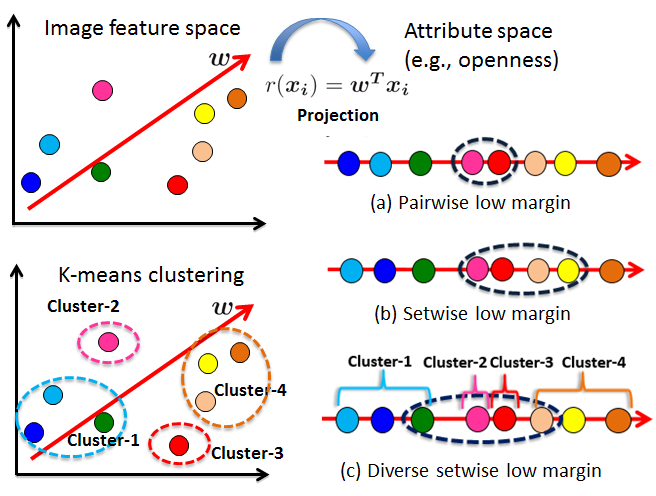
To efficiently optimize the margin component of the above equation, we project all unlabeled instances to a 1-D ordering using the current ranking function. Then, the cumulative margin of each contiguous set of k sorted items is evaluated in succession. The operation takes linear time. For further details on the algorithm, see: H.Yu, SVM selective sampling for ranking with application to data retrieval, Proceedings of the ACM Conference on Knowledge Discovery and Data Mining (KDD), ACM, 2005.
To optimize both the margin and clustering based components of the above equation, we propose a search strategy that builds on the technique (from Yu's paper) outlined above. The idea is as follows.
Only a strictly rank-contiguous set will minimize the total margin; yet there may not be a rank-contiguous set for which diversity holds. Thus, we scan contiguous sets in sequence, always maintaining the current best margin score. If our current best is not diverse, we perturb it using the next nearest sample until it is. The key to efficiency is to exploit the 1D ordering inherent in attribute ranks, even though the clusters are in the high-dimensional descriptor space. For pseudocode detailing this approach, see our supplementary material. For the actual code (in Matlab) of the active selection approach, see here.
Experimental Setup
Datasets used:
- Shoes [Kovashka12] - 14,658 shoe images, 10 attributes.
- OSR [Oliva01] - 2,688 images from Outdoor Scene Recognition, 6 attributes.
- PubFig [Kumar09] - 772 images from Public Figures dataset, 11 attributes.

Offline and Live Experiments:
We conduced both Offline and Live experiments. For Offline experiments, we used the pairwise rank labels and human confidences from WhittleSearch to compute global rankings such that we have "true" comparative labels and just reveal them to active learners when requested.
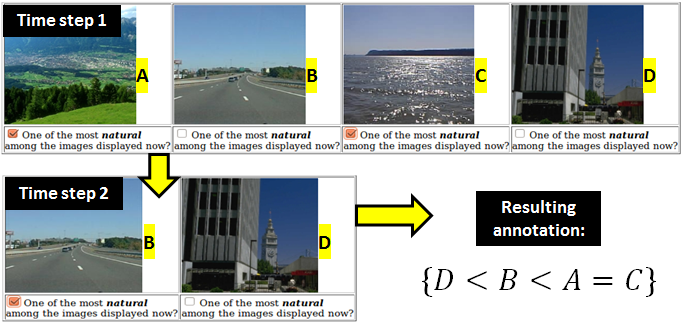
For Live experiments, we used Amazon MTurk to present image examples to human annotators. We let our methods select images for which we have no data on yet, and request labels in through a cascading UI: We ask annotators to select from a set images, the ones with the most amount of some attribute. We then repeat this with the remaining, unchecked images until all our labeled. This UI is intuitive and easy for the human to understand as well as allows for equivalence relations. Our UI code can be found here.
Baselines:
We compare our diverse setwise low margin approach with five other approaches:
- Passive ? Select set at random (status quo).
- Diverse only ? Select set from different clusters, but ignore margins.
- Wide margin ? Select set with widest, rather than lowest, margins.
- Pairwise low margin ? Select k/2 pairs with pairwise lowest margin.
- Setwise low margin [Yu, KDD05] ? Select set with lowest mutual margin.
Experimental Results
We evaluated the accuracy of our method by using a held-out set of test images (apart from the unlabeled pool of images from which we select comparisons) with pre-established "ground-truth" rank values. We then apply the learned ranking function to the test set and compare the resulting rankings with the ground-truth labels via Kendall's tau rank correlation coefficient.
The results below show that with our approach, we reduce annotation costs - defined as the number of labeling iterations - compared to competing methods and on average reduce costs by 39% compared to standard passive approach.
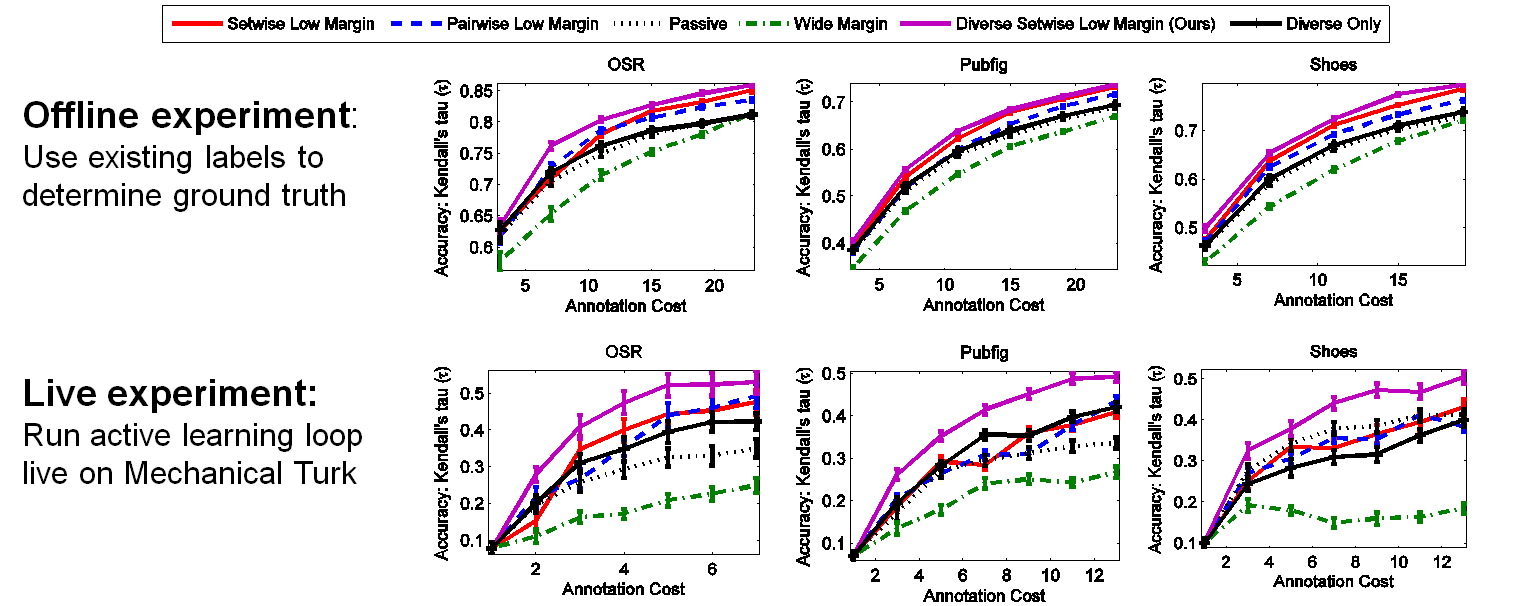
The plots above show results averaged across all attributes per data set. For result per attribute, see our supplementary material.
Publication
Beyond Comparing Image Pairs: Setwise Active Learning for Relative Attributes. Lucy Liang and Kristen Grauman. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, June 2014.
[pdf]
[supplementary]
[poster]
[DSLM Active Selection Code]
[User Interface Code]
Any questions, please contact lliang (at) cs (dot) utexas (dot) edu.