Collect-Cut:
Segmentation with Top-Down Cues
Discovered in
Multi-Object Images
Yong Jae Lee and
Kristen Grauman
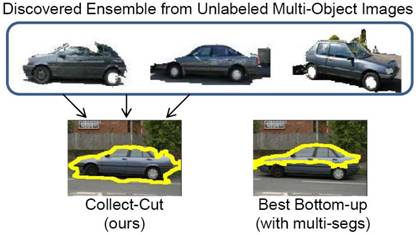
Summary
We present a method to segment a
collection of unlabeled images while exploiting automatically discovered
appearance patterns shared between them.
Given an unlabeled pool of multi-object images, we first detect any visual
clusters present among their sub-regions, where inter-region similarity is
measured according to both appearance and contextual layout. Then, using each initial segment as a seed,
we solve a graph cuts problem to refine its boundary---enforcing preferences to
include nearby regions that agree with an ensemble of representative regions
discovered for that cluster, and exclude those regions that resemble familiar
objects. Through extensive experiments,
we show that the segmentations computed jointly on the collection agree more
closely with true object boundaries, when compared to either a bottom-up
baseline or a graph cuts foreground segmentation that can only access cues from
a single image.
System Overview

We
use graph cuts to minimize an energy function that encodes top-down object
cues, entropy-based background cues, and neighborhood smoothness
constraints. A node in the graph corresponds
to a superpixel and an edge between two nodes
corresponds to the cost of a cut between two superpixels. In this example, suppose the familiar object
categories are building and road.
(a) A set of k clusters of regions. We
employ our algorithm for “context-aware” visual category discovery to map an
unlabeled collection of images to a set of clusters.
(b)
An initial region from the pool generated from
multiple-segmentations.
(c) Ensemble cluster
exemplars which we use to encode top-down cues.
For each cluster, we
extract r representative region
exemplars to serve as its top-down model of appearance. Though individually the ensemble's regions
may be short of an entire object, as a group they represent the variable
appearances that arise within generic intra-category instances. When refining a region's boundaries, the idea
is to treat resemblance to any one of
the representative ensemble regions as support for the object of interest.
(d) Background exemplars
and entropy map to encode background preference for familiar objects. Darker regions are more “known”, i.e., more
likely to be background.
(e) Soft boundary map
produced by the gPb
detector. Our smoothness term favors
assigning the same label to neighboring superpixels
that have similar color and texture and have low probability of an intervening
contour.
(f) Our final refined
segmentation for the region under consideration. Note that a single-image graph-cuts
segmentation using the initial seed region as foreground and the remaining
regions as background would likely have oversegmented
the car, due to the top half of the car having different appearance from the
seed region.
Results
We tested
our method on two datasets: MSRC-v2 and MSRC-v0.
Quantitative
Results

The figure
above shows segmentation overlap scores
for both datasets, when tested (a) with the context of familiar objects or (b)
without. Higher values are better---a
score of 1 would mean 100% pixel-for-pixel agreement with ground truth object
segmentation. By collectively segmenting
the images, our method's results (right box-plots) are substantially better
aligned with the true object boundaries, as compared to both the initial
bottom-up multiple segmentations (left box-plots), as well as a graph cuts
baseline that can use only cues from a single image at once (middle box-plots).
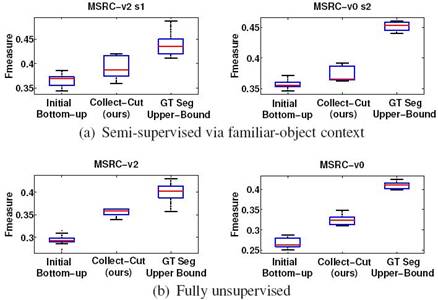
The
figure above shows the impact of collective segmentation on discovery accuracy,
as evaluated by the F-measure (higher
values are better). For discovery, we
plug in both (a) our context-aware clustering algorithm, and (b) an
appearance-only discovery method. In
both cases, using our Collect-Cut algorithm to refine the original bottom-up
segments yields more accurate grouping.
Qualitative Results

Qualitative
comparison: our results vs. the best corresponding segment available in
the pool of multiple-segmentations. The first 8 columns are examples where our
method performs well, extracting the true object boundaries much more closely
than the bottom-up segmentation can. The
last 2 columns show failure cases
for our method. It does not perform as
well for images where the multiple objects have very similar color/texture, or
when the ensembles are too noisy.

Examples
of high quality multi-object segmentation results. We aggregate our method’s refined object
regions into a single image-level segmentation.
Publication
Collect-Cut:
Segmentation with Top-Down Cues Discovered in Multi-Object Images
[pdf]
[supp] [data]
Yong Jae Lee and Kristen Grauman
In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA,
June 2010.
Related
Paper:
Object-Graphs for
Context-Aware Category Discovery [pdf]
[project
page]
Yong Jae Lee and Kristen Grauman
In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA,
June 2010.