Sudheendra Vijayanarasimhan, Prateek Jain and Kristen Grauman
Department of Computer Sciences,
University of Texas at Austin
In active learning, most approaches focus on selecting a single unlabeled instance to query at at time and assume that all examples require the same amount of manual effort to label. However, for systems such as Mechanical Turk or LabelMe which provide access to multiple annotators simultaneously a batch selection is more advantageous. Further, the cost associated with labeling different examples often varies, sometimes significantly. For instance, the longer the video, the longer it will take to watch it and annotate its contents; the more sophisticated or time-consuming the image query, the more we may need to pay a human labeler to answer it.
In our previous work we have shown that an active learning method needs to take the variable costs into account to provide accurate gains.
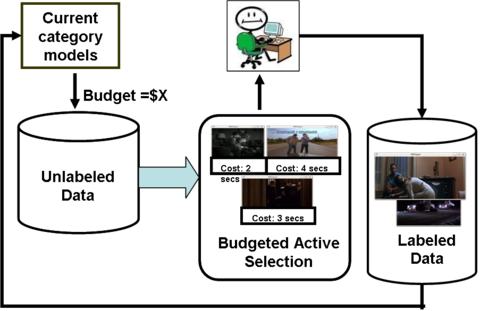
In this paper, we consider the problem where at each iteration the active learner must select a set of examples meeting a given budget of supervision, where the budget is determined by the funds (or time) available to spend on annotation.
We formulate the budgeted selection task as a continuous optimization problem where we determine which subset of possible queries should maximize the improvement to the classifier's objective, without overspending the budget.
Let ![]() represent the set of labeled examples and their labels respectively,
represent the set of labeled examples and their labels respectively, ![]() the set of unlabeled examples and
the set of unlabeled examples and
![]() denote their manual effort costs and
denote their manual effort costs and ![]() represent the selection budget for the current iteration. We want to
select a set of examples and their optimistic labels
represent the selection budget for the current iteration. We want to
select a set of examples and their optimistic labels
![]() such that together they yield the maximal reduction in the objective, as measured by the objective before their addition to the labeled set versus the objective after they are added.
such that together they yield the maximal reduction in the objective, as measured by the objective before their addition to the labeled set versus the objective after they are added.
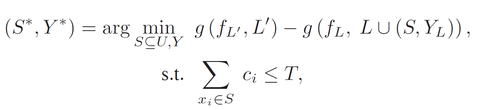
where
![]() is the labeled set expanded with some label assignment on
is the labeled set expanded with some label assignment on ![]() .
.
The function ![]() is based on the SVM objective function, where
is based on the SVM objective function, where ![]() denotes the SVM hyperplane parameters, and measures the sum of the margin of the solution when trained on the set
denotes the SVM hyperplane parameters, and measures the sum of the margin of the solution when trained on the set ![]() and the empirical risk evaluated on set
and the empirical risk evaluated on set ![]() .
Because we incorporate the predicted change in the model that the candidate examples will induce, the method is far-sighted in terms of the effects on the entire batch.
.
Because we incorporate the predicted change in the model that the candidate examples will induce, the method is far-sighted in terms of the effects on the entire batch.
By introducing indicator variables for unlabeled examples and relaxing the above integer optimization to continuous values we devise an efficient alternating minimization algorithm for obtaining the optimal query set ![]() .
.

Our approach can be used for active training of any SVM classification problem. The inputs are an initial training set containing some labeled examples of the categories of interest, the number of selection iterations, an unlabeled pool of data, and the available budget. In practice, one would set this budget according to the resources available -- for example, the money one is willing to spend on Mechanical Turk to get a training set for the next object recognition challenge.
We construct the initial classifier, and then for each iteration, select a set of examples to annotation. For unlabeled data with non-uniform costs, each resulting request will consist of a variable number of items (images, video clips). Once these tasks are completed (either sequentially, or in parallel by a team of annotators), the labeled set is expanded accordingly, the classifier is updated, and budgeted selection repeats.
The final output is the trained classifier.
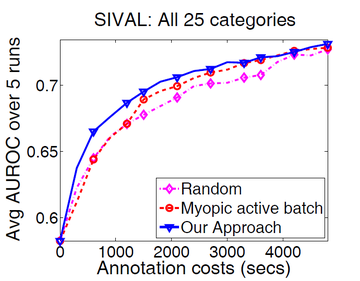
We show results for budgeted active selections for two different tasks in vision both of which require a lot of supervision: video (action) recognition, image recognition. We use the 8-class Hollywood dataset for action recognition and the 25-class SIVAL dataset for object recognition. The cost of an annotation for videos is set to the length of the video and we use the annotation costs provided by [21] for SIVAL.
 |
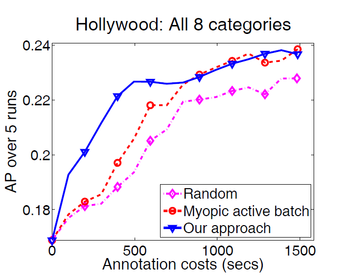 |
We set the budget ![]() to 300 secs such that in 20 iterations all unlabeled examples will be exhausted and plot the accuracies of our approach, a random baseline and a myopic active baseline against the cost of the selected annotations. Our approach is consistently
better than both baselines on both datasets as seen in the average result over all categories in the datasets.
to 300 secs such that in 20 iterations all unlabeled examples will be exhausted and plot the accuracies of our approach, a random baseline and a myopic active baseline against the cost of the selected annotations. Our approach is consistently
better than both baselines on both datasets as seen in the average result over all categories in the datasets.
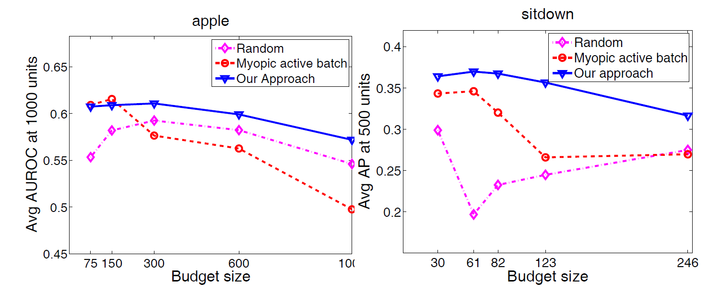
The plot shows the performance of the active selections as a function of increasing budget ![]() . Being able to set a large budget is very useful for practical applications since one could farm out many actively selected jobs in parallel, and assure that the large
budget is not wasted. The quality of our far-sighted selections remains more stable for larger budgets compared to the baselines making our approach more suited to large budget selections than the baselines.
. Being able to set a large budget is very useful for practical applications since one could farm out many actively selected jobs in parallel, and assure that the large
budget is not wasted. The quality of our far-sighted selections remains more stable for larger budgets compared to the baselines making our approach more suited to large budget selections than the baselines.
 |
 |
| ``bluescrunge'' category from SIVAL. | ``stand up'' action from Hollywood. |
|---|
Example active selections made by our approach and the baselines for a few categories on both datasets. Left: Our approach is able to select both less expensive and more informative examples, while sticking within the allowed budget as closely as possible. Right: The clips shown in the image are of different lengths, and our approach selects a combination of shorter informative ones in this instance, while the baselines tend to choose more expensive examples.