Inferring
Unseen Views of People
Chao-Yeh Chen and
Kristen Grauman
The University of Texas at Austin

We
pose unseen view synthesis as a probabilistic tensor completion problem. Given
images of people organized by their rough viewpoint, we form a 3D appearance
tensor indexed by images (pose examples), viewpoints, and image positions.
After discovering the low-dimensional latent factors that approximate that
tensor, we can impute its missing entries. In this way, we generate novel
synthetic views of people—even when they are observed from just one camera viewpoint. We
show that the inferred views are both visually and quantitatively accurate.
Furthermore, we demonstrate their value for recognizing actions in unseen views
and estimating viewpoint in novel images. While existing methods are often
forced to choose between data that is either realistic or multi-view, our
virtual views offer both, thereby allowing greater robustness to viewpoint in novel
images.
Problem: dilemma for human images!
Though
we have lots of images for human poses, but they are either:
|
- Realistic
snapshots, but limited views. |
-
Multi-view imagery, but artificial lab conditions. |


Our Idea: infer images of people in
novel viewpoints
|
|
Highlights: |

Approach
Overview

-Infer the pose in missing view with tensor
completion.
(1)
Representing poses from
different views
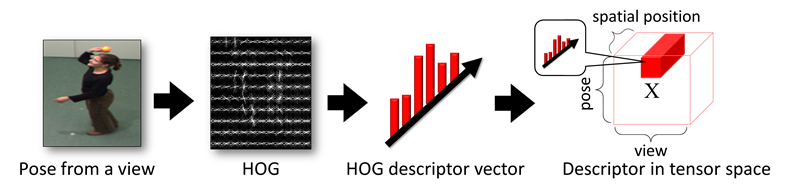
- Pose = person captured in one instant in
time.
- Compute HOG descriptor for poses in all
available views.
- Situate them in tensor according to
(discretized) viewpoint.
(2)
Unseen view
inference as tensor completion problem
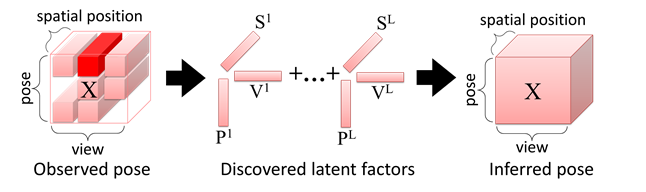
- Recover the latent factors for the 3D
tensor X.
- Use latent factors to impute the pose in
unseen views.
- Solve with probabilistic factorization [Xiong et al. 2010].
(3)
Learning with
unsynchronized single-view images
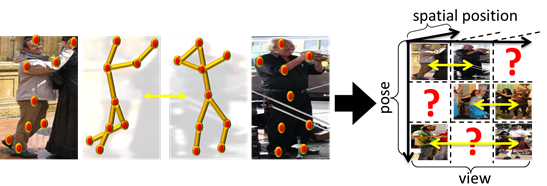
Infer new views for
snapshots observed from just a single viewpoint.
- Beyond synchronized multi-view data, we want to
learn from single-view “in the wild” snapshots of people.
- Link snapshots with similar 3D pose, but
different viewpoint.
Results
Datasets: IXMAS multi-view images
(Weinland et al.) and H3D Flickr images (Bourdev et al.).
Visualizing
inferred views
- visualize the inferred views using inverted-HOG
(Vondrick et al.).
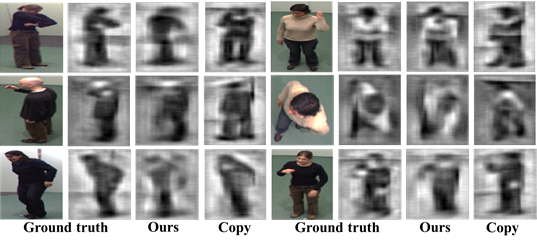
Visualization
of inferred unseen views in IXMAS dataset.

Visualization
of inferred unseen views in H3D dataset.
Accuracy of
inferred views
- Our inferred views have lowest Summed Square Difference
(SSD) compared to two baselines.
- Memory: memory-based tensor completion.
- Copy: copy observed images from nearby views.
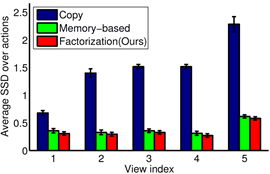
Error
in inferred views.
Impact of
data sparsity
- Our method’s accuracy is fairly stable up
until about 40% (i.e., when 60% of the tensor is unobserved).
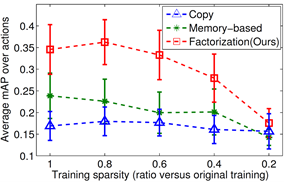
Accuracy in unseen views
as a function of tensor sparsity.
Application:
Recognizing actions in unseen views
- Use our inferred views
to train a system to recognize actions from a viewpoint it never observed in
the training images.
![]()
Action
recognition accuracy (mAP) in an unseen viewpoint on
IXMAS.
Numbers in parenthesis are standard errors.
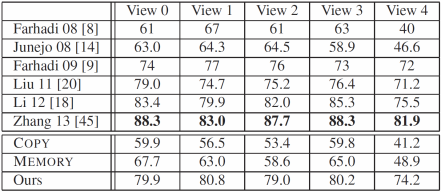
Cross-view
action recognition accuracy on IXMAS.
Application: Viewpoint estimation
- Improve viewpoint estimation by adding the
view-specific training instances created by our method with the real images.
![]()
Average
mAP, compared to view synthesis baselines with HOG
features.
![]()
Classification
accuracy vs. state-of-art with poselet features.
Conclusion
- Novel learning approach for inferring human
appearance in unseen viewpoints.
- Accommodates both synchronized multi-view and unsynchronized single-view
images.
- Valuable for viewpoint robustness in human analysis tasks on two challenging
datasets.
Download
- Paper, Supp
- Code
- Poster
- Bibtex