Shape Discovery from Unlabeled Image Collections
Yong Jae Lee and
Kristen Grauman
University of Texas
at Austin
Summary
Can
we discover common object shapes within unlabeled multi-category collections of
images? While often a critical cue at
the category-level, contour matches can be difficult to isolate reliably from
edge clutter - even within labeled images from a known class. We propose a shape discovery method in which
local appearance (patch) matches serve to anchor the surrounding edge
fragments, yielding a more reliable affinity function for images that accounts
for both shape and appearance. Spectral
clustering from the initial affinities provides candidate object clusters. Then, we compute the within-cluster match
patterns to discern foreground edges from clutter, attributing higher weight to
edges more likely to belong to a common object. In addition to discovering the
object contours in each image, we show how to summarize what is found with
prototypical shapes. Our results on
benchmark datasets demonstrate the approach can successfully discover shapes
from unlabeled images.
System Overview
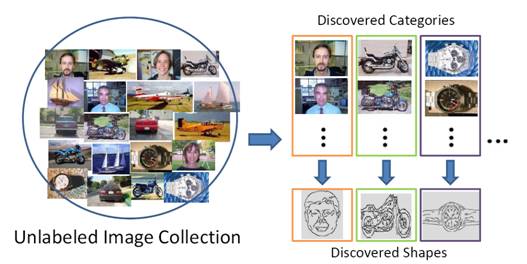
The
goal is to identify which foreground contours in each image can form high
quality clusters, and use any intra-cluster agreement to discover the
underlying prototypical shapes.
Specifically,
we want to
1)
Group
images with objects that agree in shape and appearance to discover categories.
2)
Identify
the foreground contours in each intra-cluster image to discover shape.
Semi-local Region
Features
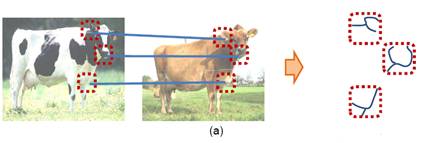
(a)
There is a limit to how much shape information can be captured with patch
matches (even if they are accurate), yet edge fragments can often be ambiguous
to match in cluttered images.
(b)
Therefore, we anchor edge fragments to patch features to select the fragments
that agree and describe the object’s shape.
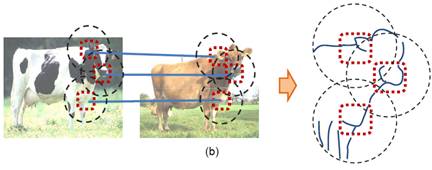
Grouping Cluttered
Images with Similar Shapes
We propose a new affinity function between two images to target
possible agreement between contours amidst clutter. (a) A feature from image X is matched to each
feature in image Y, and (b) the best matching feature in terms of local
appearance and coarse surrounding shape in Y is chosen. (c) X’s edgemap is
aligned with Y’s edgemap at the match point, and each
fragment is fitted to the nearest best matching fragment in Y. From this, we can compute a shape distance
given by the fragment matches, and an appearance distance given by the patch
matches.
We match each feature in X to a feature in Y, and average the
local appearance and shape distances to compute a single affinity score between
X and Y. We compute affinity scores
between all pairs of images, and use spectral clustering to partition the
dataset into homogeneous groups of images that have similar object appearance
and shape.
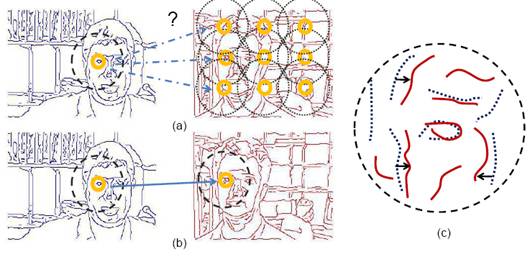
Inferring Foreground
Features
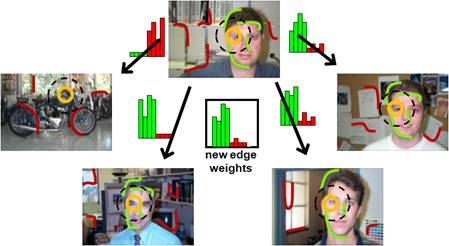
Given the discovered categories, we analyze the pattern of intra-cluster
matches to infer the foreground contours.
Specifically, given an image’s feature, we compute the median of its
best matching features across all other images within the cluster. The median ensures that high weight goes only
to those edge fragments that produce low matching costs against most cluster
members.
Evaluation
We evaluate our method on the Caltech-6 (Faces, Airplanes, Motorbikes, Cars Rear,
Watches, Ketches) and ETHZ (Applelogos, Bottles, Giraffes, Mugs, Swans) datasets. For the ETHZ images, we evaluate with
bounding box regions only (bbox) and expanded regions
(expanded) covering 4 times the initial bounding box area. We compare against state-of-the-art
appearance based systems, and a patch-only baseline, in which we use the same
steps as our method, but use only local appearance patches.
Unsupervised
Category Discovery
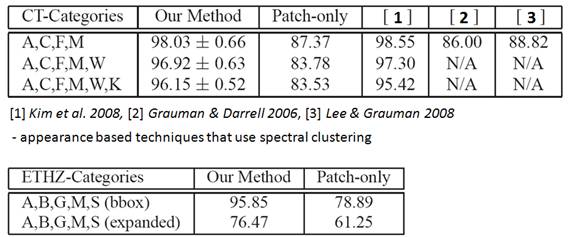
We
use cluster purity to evaluate our methods’ object category discovery. Our method is comparable or better than
related methods.
Foreground
Localization
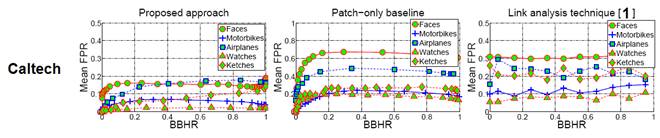
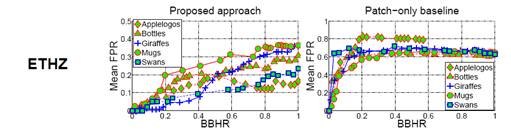
We
compute Bounding Box Hit Rate (BBHR) vs.
False Positive Rates (FPR) to evaluate our method’s foreground
localization (lower curves are better).
Our method outperforms related methods, and achieves very good
localization rates.
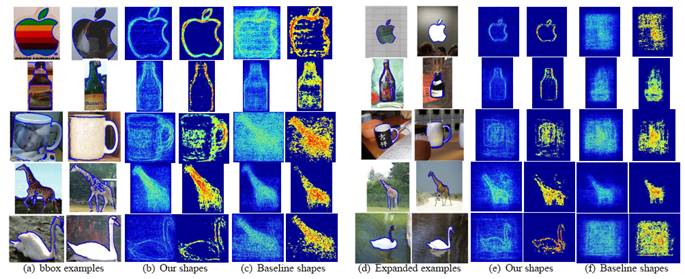
Qualitative
Results
We
show example images with discovered foreground object contours and summarized
prototypical shapes for each cluster. We
compute prototypical shapes by taking the most central image in each cluster
and matching all intra-cluster images to it using a modified chamfer distance –
each edgel’s matching cost is penalized according to
its weight. We compare against a
shape-only baseline where we form clusters using chamfer distances between
uniformly-weighted image edgemaps.

Publication
Shape
Discovery from Unlabeled Image Collections [pdf]
[supplementary
material]
Yong Jae Lee and Kristen Grauman
In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Miami Beach, Florida, June 2009.