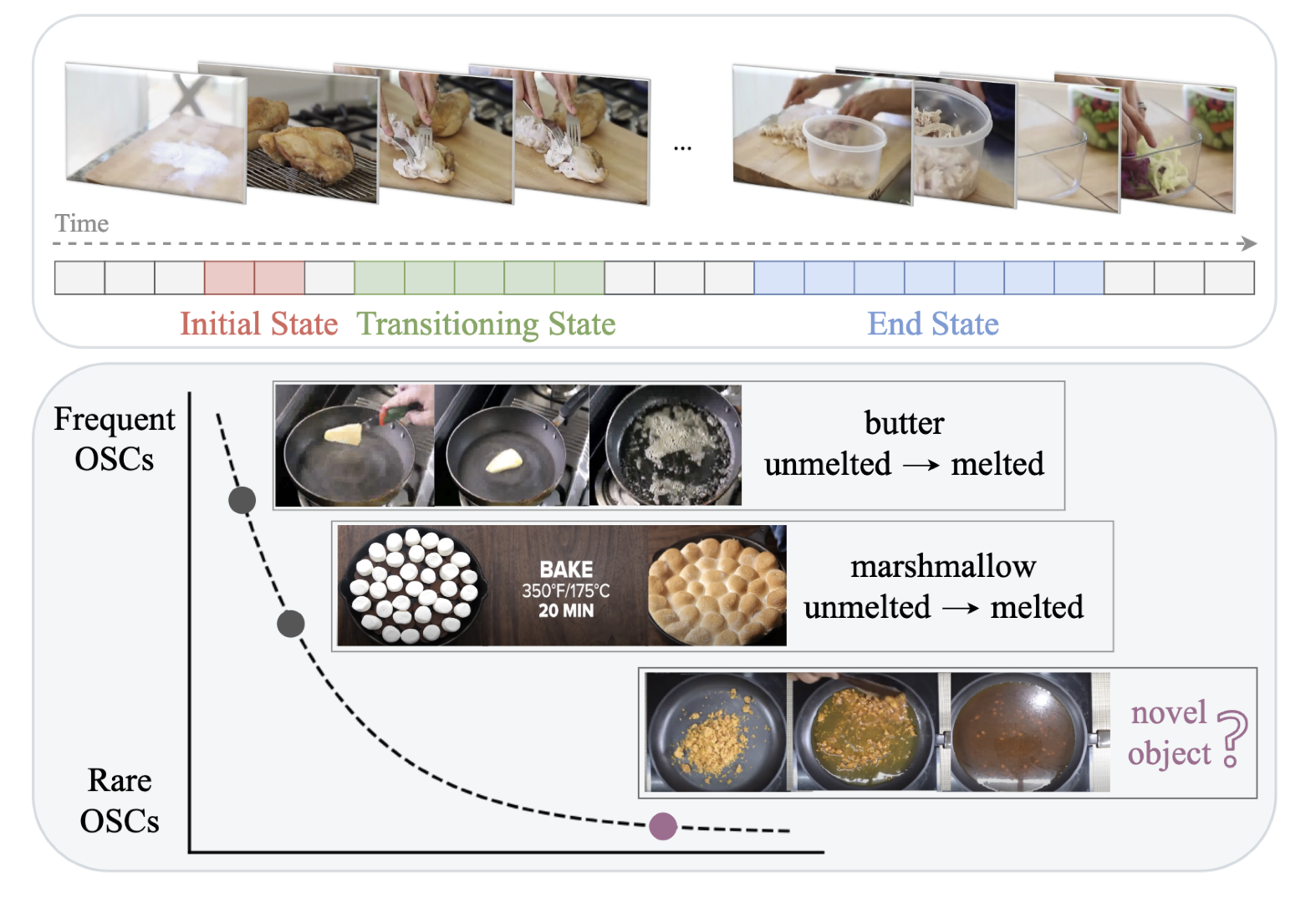
We propose a novel open-world formulation of the video OSC problem.
We present HowToChange---the first open-world benchmark for video OSC localization.
HowToChange (Training): 36,075 videos, automatically collected by LLAMA2 and pseudo-labeled with VideoCLIP
HowToChange (Evaluation): 5,424 videos, fine-grained temporal OSC state annotations done by 30 professional annotators
We introduce VidOSC, a holistic open-world learning framework
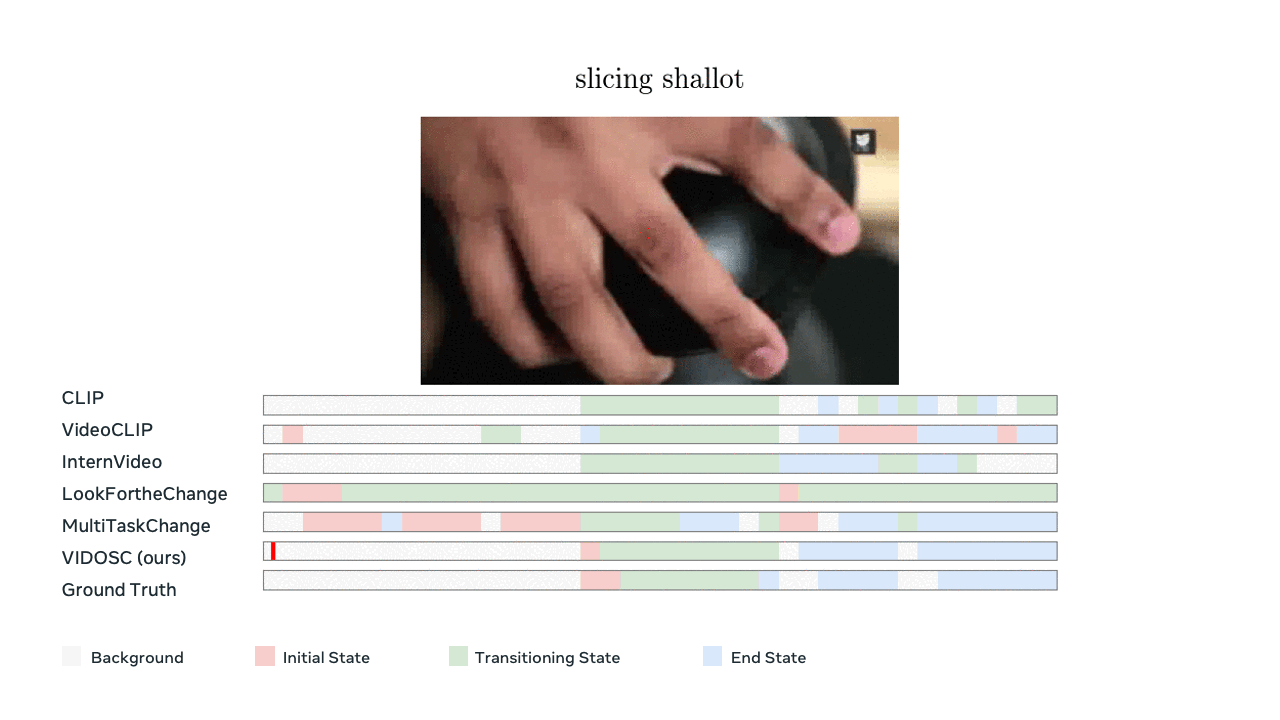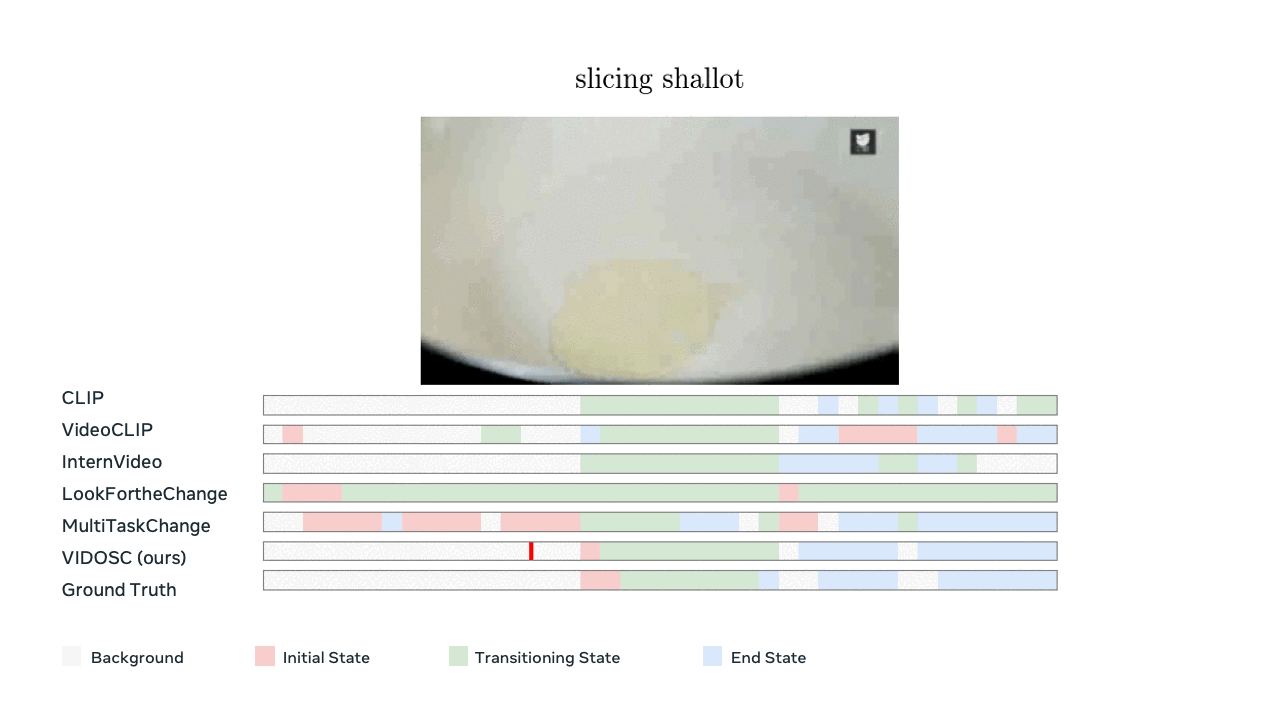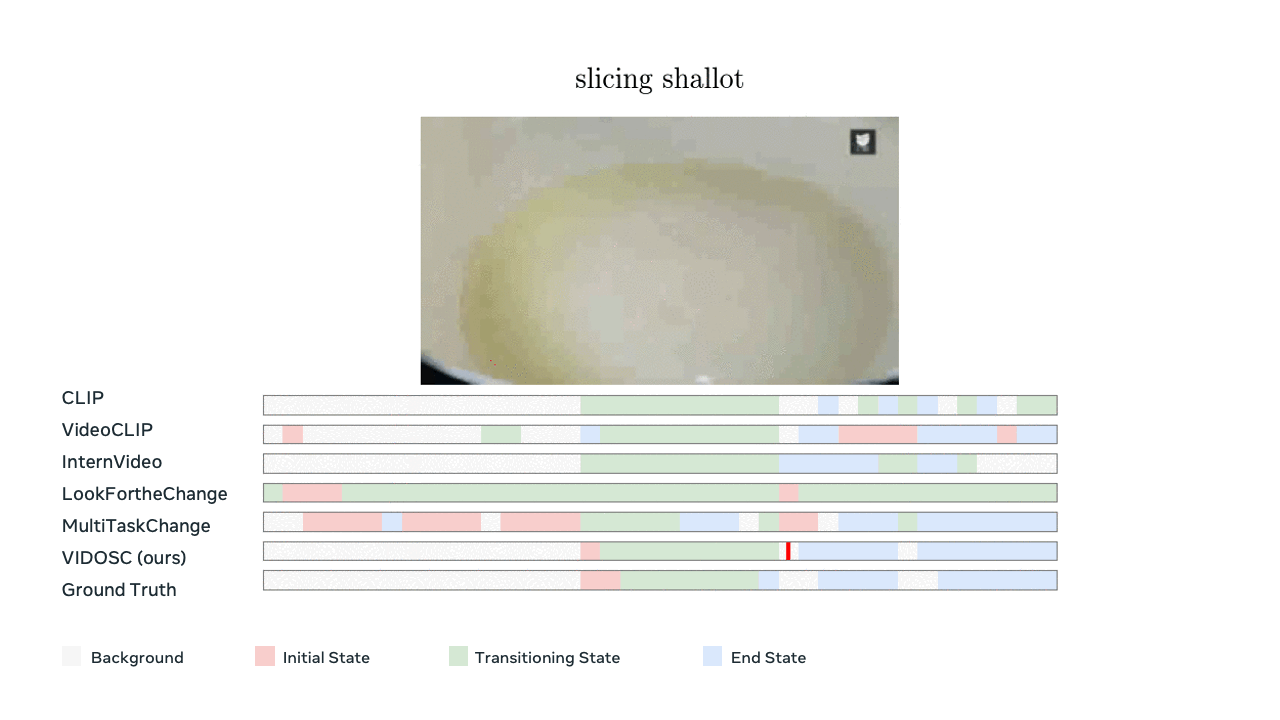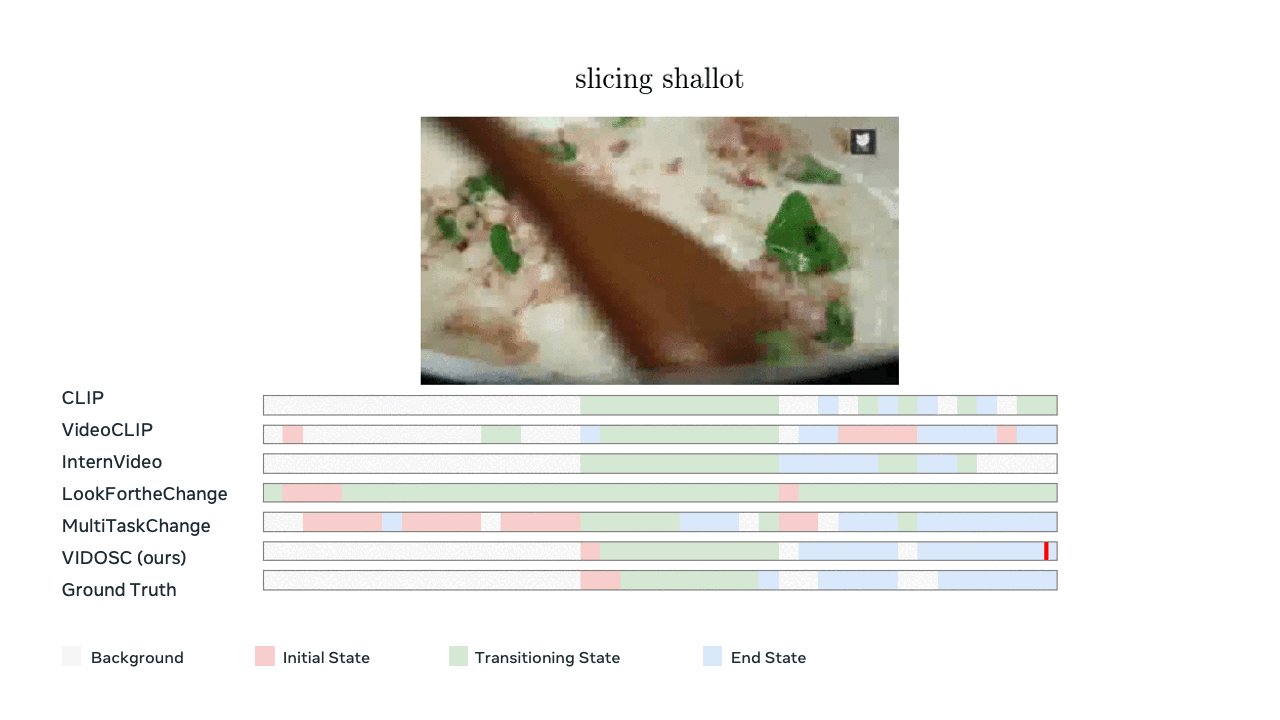
Model predictions
Known OSCs
Novel OSCs
Video
A 9-minute video designed to supplement the paper
A shorter version (5-minute video)
BibTeX
@article{xue2023learning,
title={Learning Object State Changes in Videos: An Open-World Perspective},
author={Xue, Zihui and Ashutosh, Kumar and Grauman, Kristen},
journal={CVPR},
year={2024}
}