| Changan Chen1,4, Ruohan Gao2, Paul Calamia3, Kristen Grauman1,4 |
|
1UT Austin, 2Stanford University, 3Reality Labs at Meta, 4FAIR, Meta AI Accepted at CVPR 2022 (Oral) |
|
|
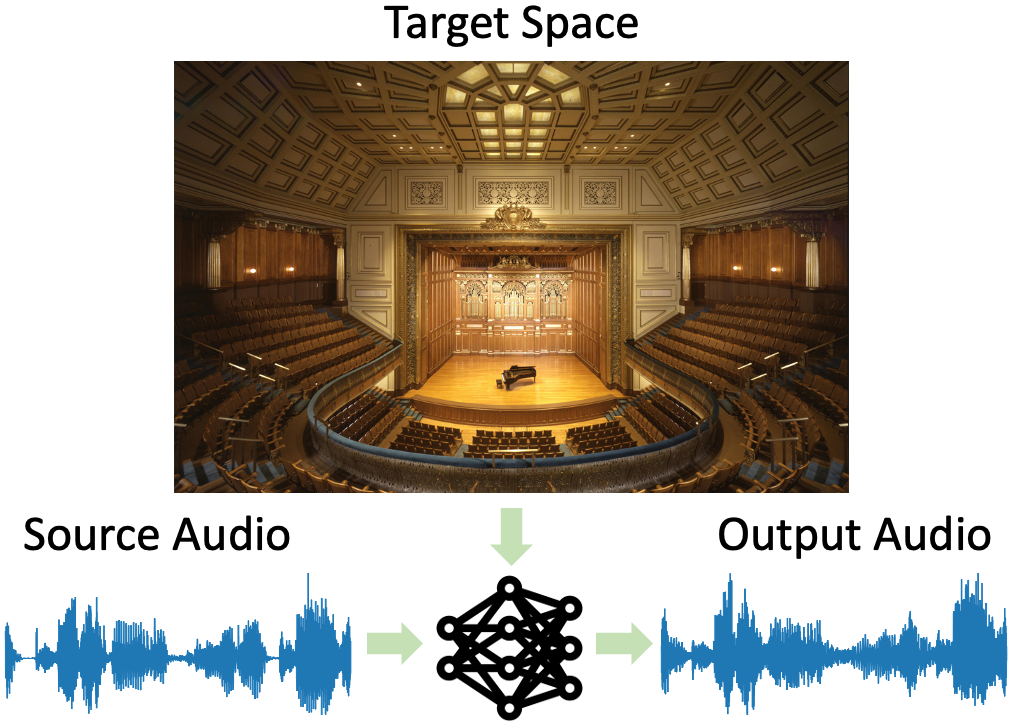
| We introduce the visual acoustic matching task, in which an audio clip is transformed to sound like it was recorded in a target environment. Given an image of the target environment and a waveform for the source audio, the goal is to re-synthesize the audio to match the target room acoustics as suggested by its visible geometry and materials. To address this novel task, we propose a cross-modal transformer model that uses audio-visual attention to inject visual properties into the audio and generate realistic audio output. In addition, we devise a self-supervised training objective that can learn acoustic matching from in-the-wild Web videos, despite their lack of acoustically mismatched audio. We demonstrate that our approach successfully translates human speech to a variety of real-world environments depicted in images, outperforming both traditional acoustic matching and more heavily supervised baselines. |
|
5-min oral presentation at CVPR 2022.
|
|
|
|
Audio-visual examples of visual acoustic matching on both synthetic data and Web videos.
|
|
|
| (1) Changan Chen*, Unnat Jain*, Carl Schissler, Sebastia Vicenc Amengual Gari, Ziad Al-Halah, Vamsi Krishna Ithapu, Philip Robinson, Kristen Grauman. SoundSpaces: Audio-Visual Navigation in 3D Environments. In ECCV 2020 [Bibtex] |
| (2) Ruohan Gao, Changan Chen, Carl Schissler, Ziad Al-Halah, Kristen Grauman. VisualEchoes: Spatial Image Representation Learning through Echolocation. In ECCV 2020 [Bibtex] |
| (3) Changan Chen, Sagnik Majumder, Ziad Al-Halah, Ruohan Gao, Santhosh Kumar Ramakrishnan, Kristen Grauman. Learning to Set Waypoints for Audio-Visual Navigation. In ICLR 2021 [Bibtex] |
| (4) Changan Chen, Ziad Al-Halah, Kristen Grauman. Semantic Audio-Visual Navigation. In CVPR 2021 [Bibtex] |
| (5) Changan Chen, Wei Sun, David Harwath, Kristen Grauman Learning Audio-Visual Dereverberation. In arxiv 2021 [Bibtex] |
| UT Austin is supported in part by DARPA Lifelong Learning Machines. |
| Copyright © 2020 University of Texas at Austin |