Watching
Unlabeled Video Helps Learn
New Human Actions from Very Few Labeled Snapshots
Chao-Yeh Chen
and Kristen Grauman
University of Texas at Austin
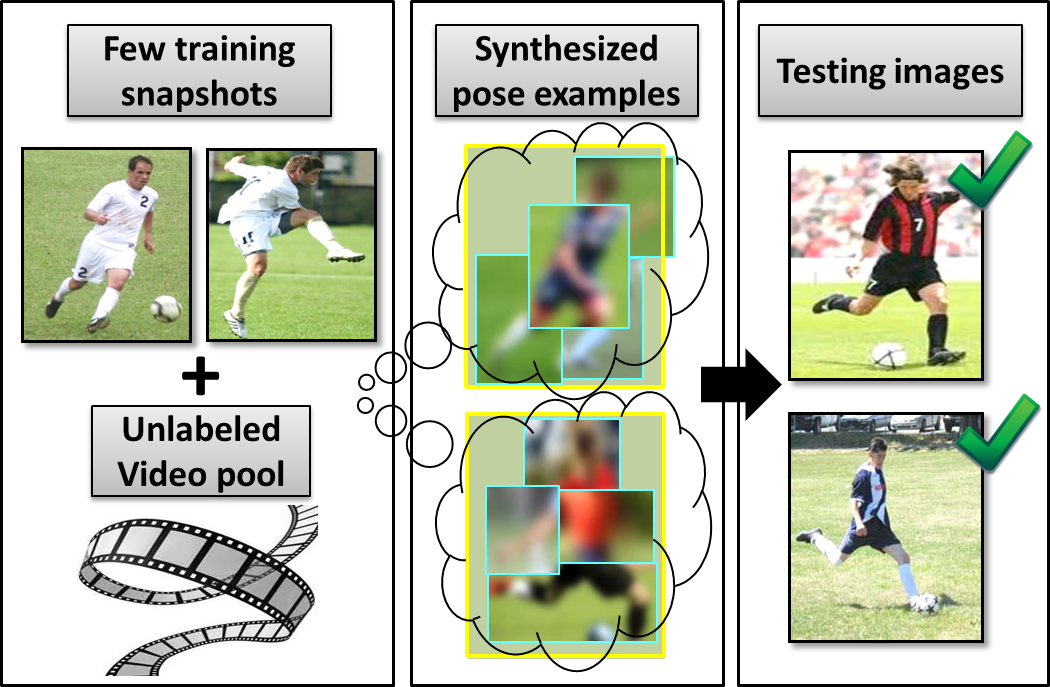
Our approach learns about human pose dynamics from unlabeled video, and then leverages that knowledge to train novel action categories from very few static snapshots. The snapshots and video (left) are used together to extrapolate “synthetic” poses relevant to that category (center), augmenting the training set. This leads to better generalization at test time (right), especially when test poses vary from the given snapshots.
Jump to:
Problem
Learn/recognize actions from static images:
-
Useful for object and scene recognition.
-
Video data collection prone to “staged” activity.
-
Labeling training videos is expensive.

Actions in static images
Problems of static snapshots:
-
May have only few training examples for some actions.
-
Often limited to "canonical" instances of the action.

Limited "canonical" instances(e.g. images in the red
box) of the action.
Our idea:
Let the system:
-
Watch unlabeled videos to learn how human poses change over time.
-
Infer nearby poses to expand the sparse training snapshots.
Related works
-
Learn actions with discriminative pose and appearance features.
e.g. [Maji et al. 2011, Yang et al. 2010, Yao et al. 2010, Delaitre et al. 2011]
Expand training data by mirroring images and videos.
e.g. [Papageorgiou et al. 2000, Wang et al. 2009]
Synthesize images for action recognition and pose estimation.
e.g. [Matikainen et al. 2011, Shakhnarovich et al. 2003,Grauman et al. 2003, Shotton et al. 2011,]
Ours: expanding the training set for “free” via pose dynamics learned from unlabeled data.
Approach
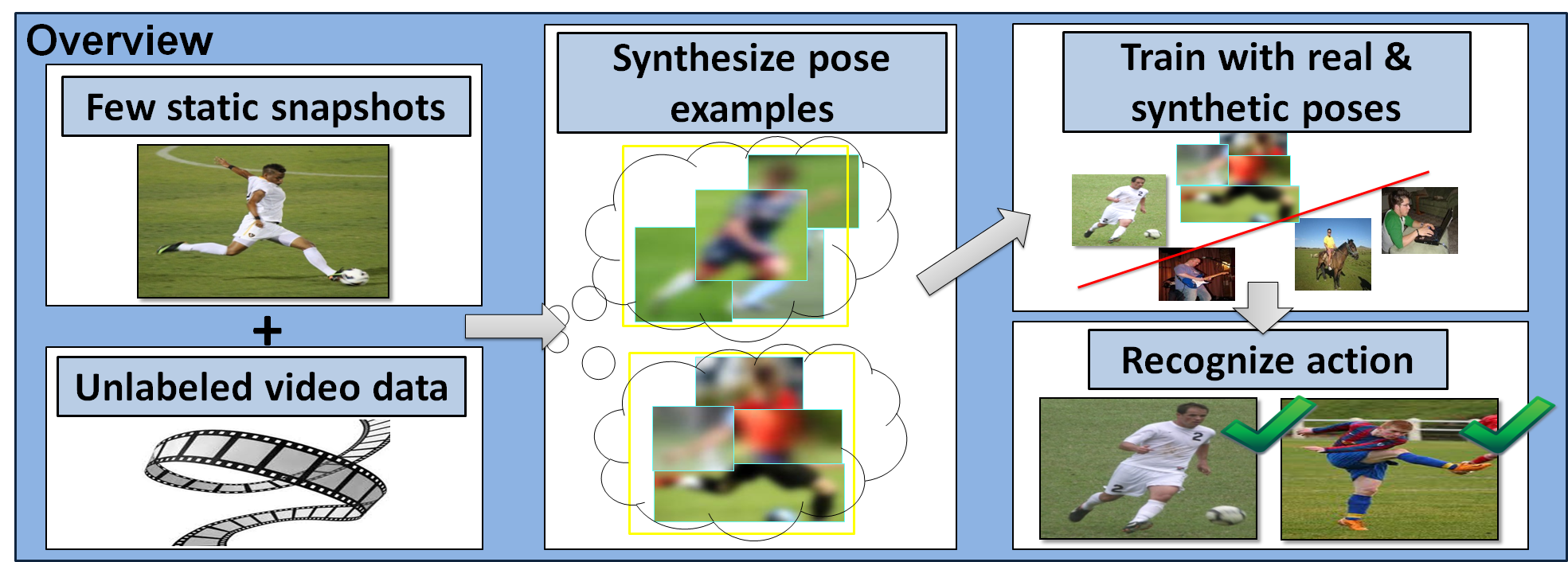
 Assumptions:
Assumptions:
-
Videos cover the space of human pose dynamics.
-
No action labels are given.
-
People are detectable and trackable.

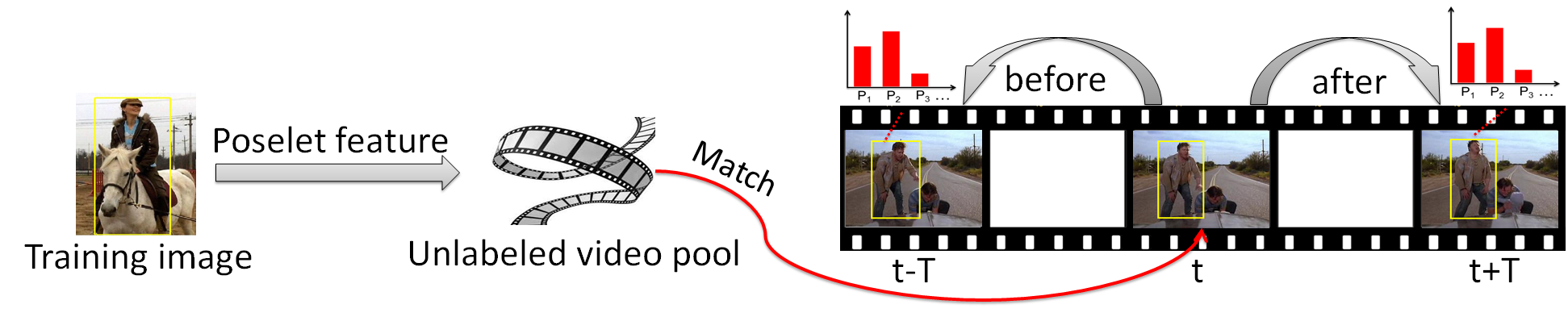
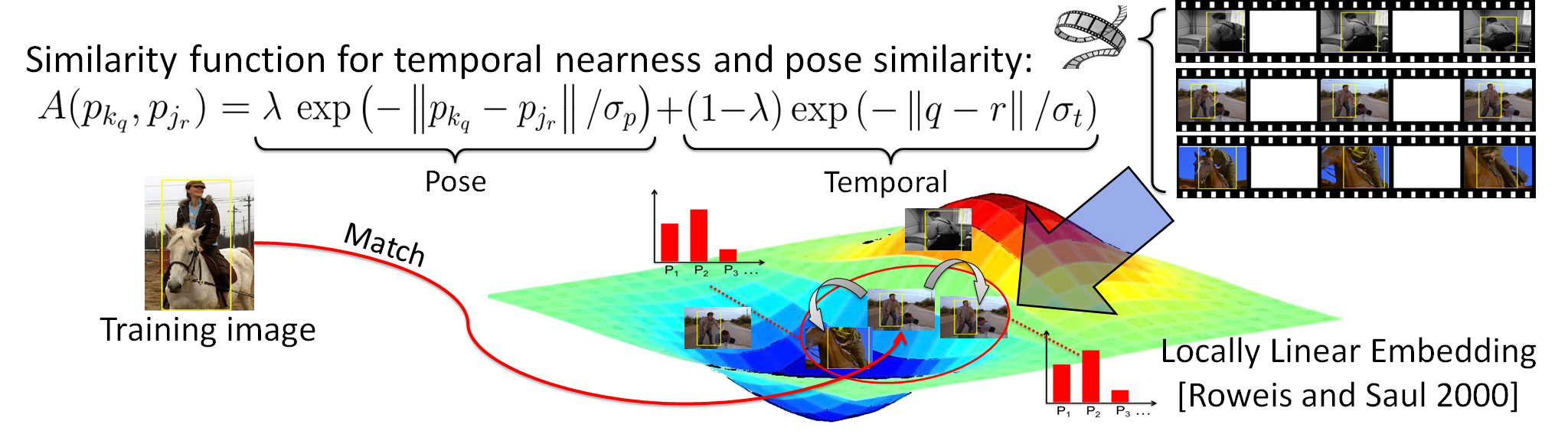
Two strategies to generate synthetic pose examples:
1) Example based strategy.
2) Manifold based strategy.


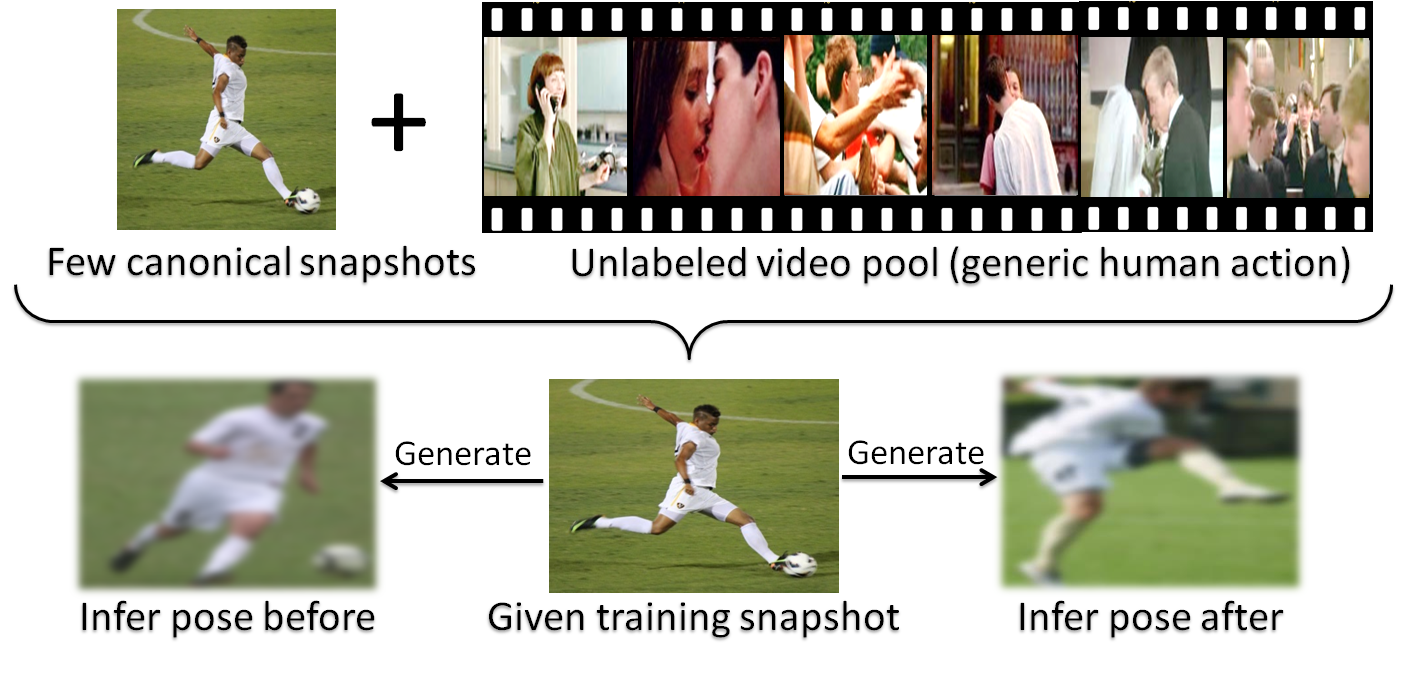
- For each static training snapshot, find the matched frame in the video, then extract the pose feature from images of T frames before and after as synthetic pose features.

- Compute the similarity score between any two frames in the video based on temporal nearness and pose similarity. Then map all frames into a nonlinear manifold space.
- For each static training snapshot, find the matched frame in the video, then extract the pose feature from the neighborhood images in the manifold space as synthetic pose features.
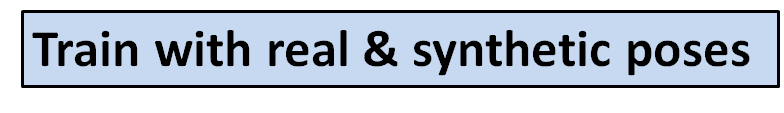
- Train the classifier with real poses from static snapshot and our synthetic pose examples.
- By adding our synthetic pose examples, we provide better coverage of pose feature space for the action model.
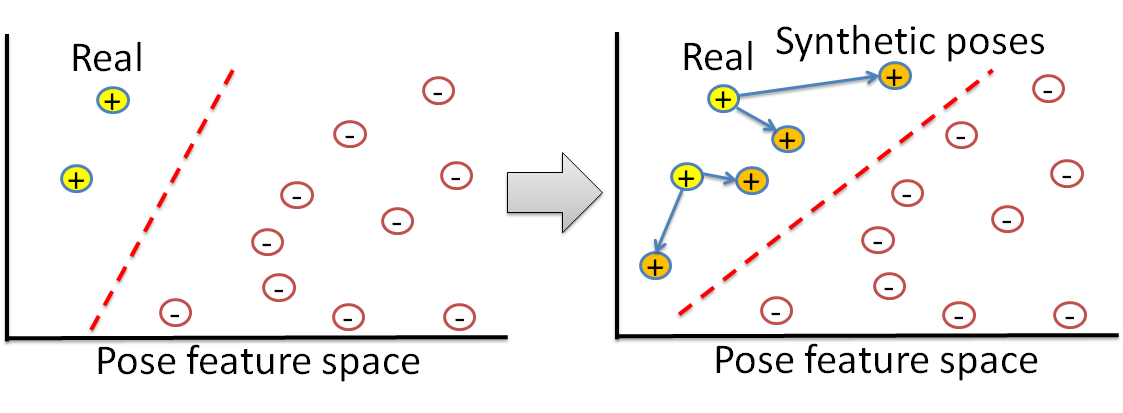
- Use domain adaptation to account for discrepancy between static images and frames from videos. We treat the frames from video as source domain and static images as target domain.
Results
Datasets
- Two images dataset: PASCAL VOC 2010 action recognition dataset and 10 selected verbs from Stanford 40 Actions dataset.
- Use Hollywood Human Actions dataset as unlabeled video pool.
- Only one verb(answering phone) overlap between two image datasets and the video dataset. Test our method in a category independent way.

Recognizing activity in images
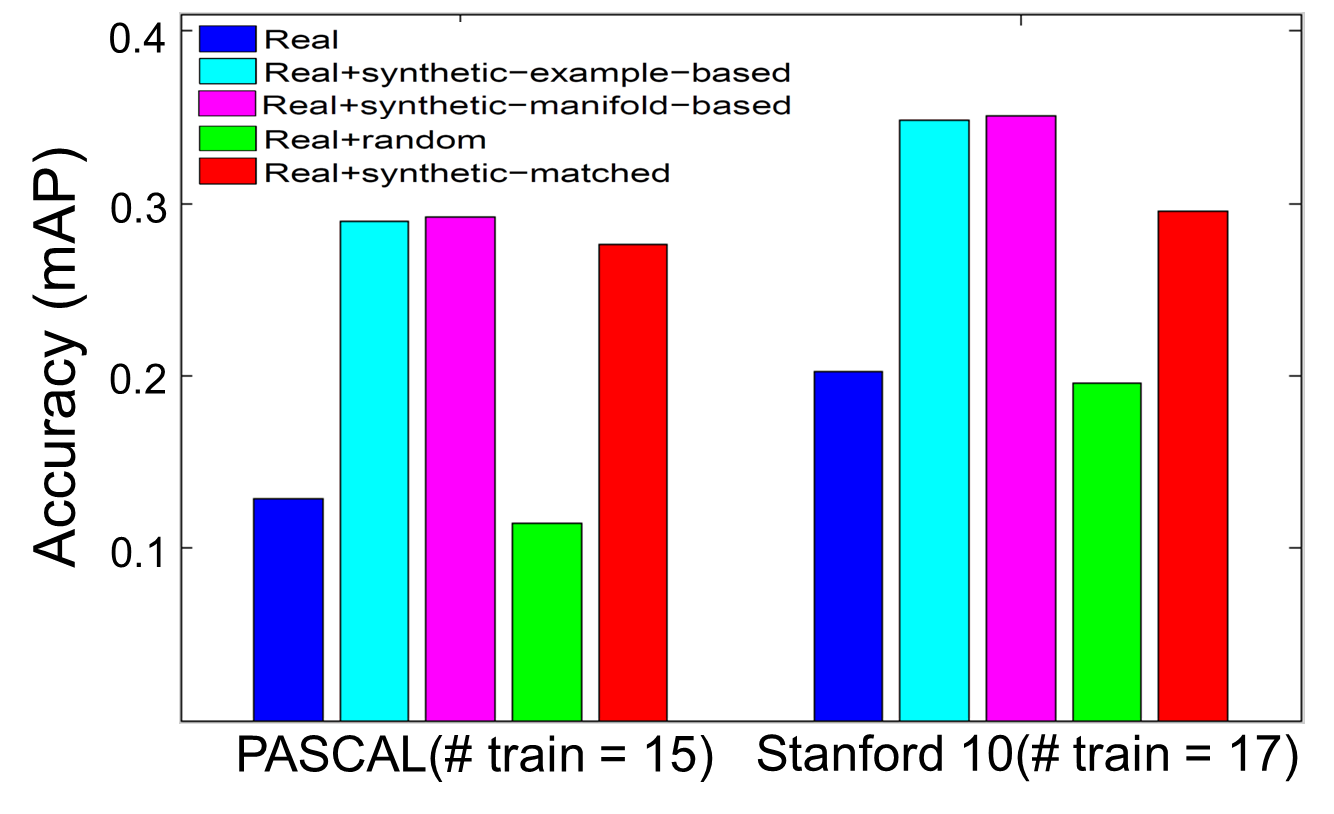
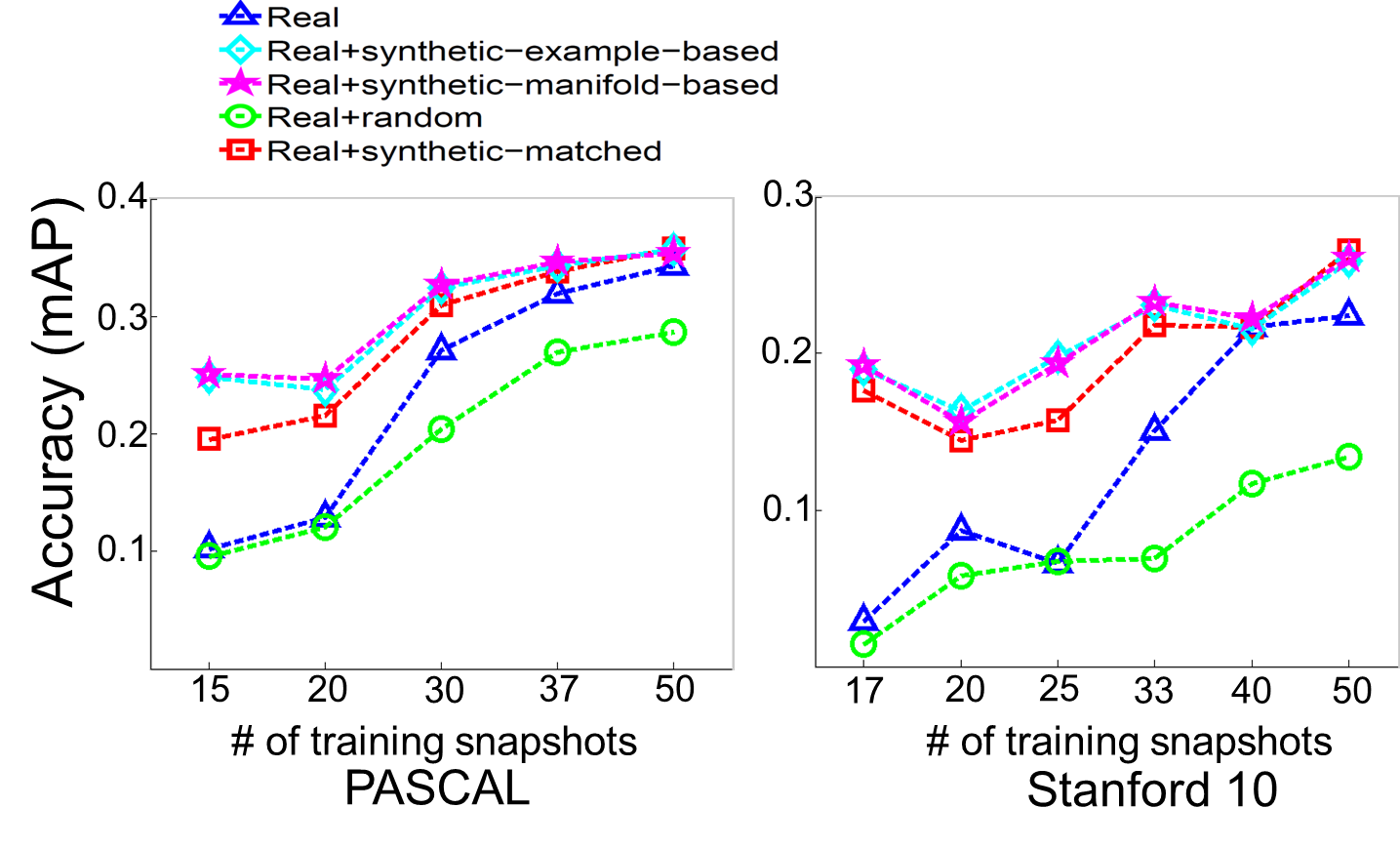
- We show significant improvement in accuracy while adding our synthetic pose examples.
- Overall accuracy between our example-based strategy and manifold-based strategy is similar. However, we find our manifold-based strategy provides more advantage in actions with repeated motion such as running or using computer because it captures temporal pose dynamics and appearance variance.
- To verify our methods not only get advantages from having more training examples, we randomly select frames from videos and use them to generate synthetic pose examples. As expected, the accuracy is lower than using original static snapshots.
- If limiting our method to only have the matched frames that have most similar pose examples to original static snapshots, we get improvement in accuracy. However, accuracy is lower than using our synthetic pose examples.
- If we keep increasing the size of given training snapshots, the accuracy of our methods will be similar to use only original static snapshots. It is because the static snapshots already cover the pose feature space for the action model well.
Pose diversity in training
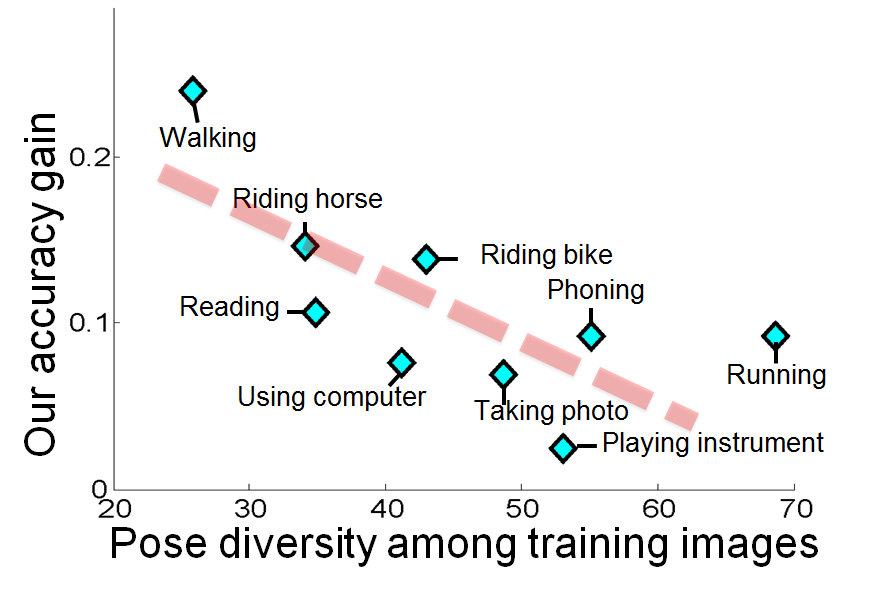
- In PASCAL dataset, images of walking have lowest pose diversity while images of running have highest pose diversity.
- Accuracy gain shows the difference between accuracy of our example based strategy and training the classifier with original static snapshots.
- Our method most benefit for actions that lack diversity in training images.
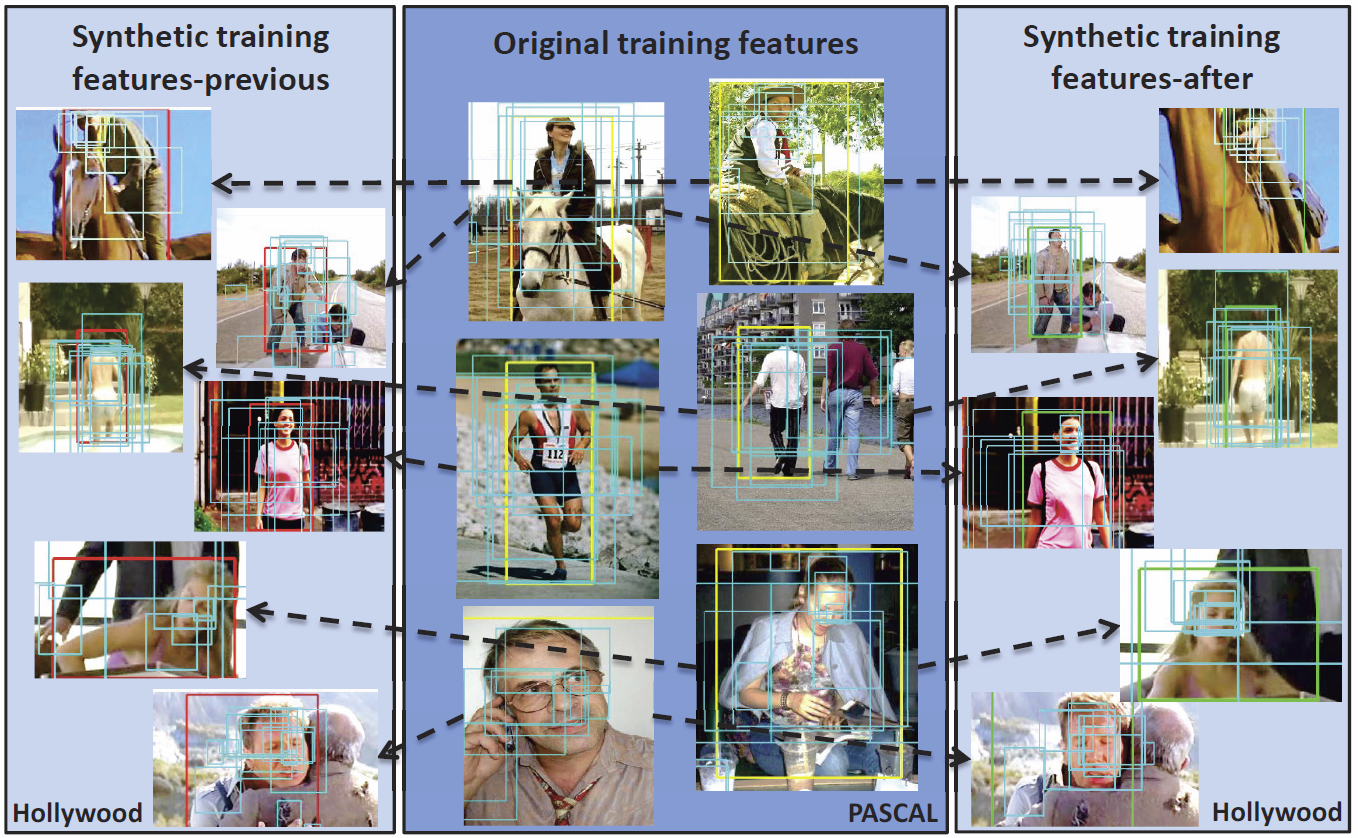
Synthetic examples
- Qualitative synthetic examples in our example based strategy.
- In some cases images of synthetic pose examples are coming from similar action category as static snapshots such as both images from second row show a man walking back to us.
- In some cases images of synthetic pose examples are coming from different action category as static snapshots such as in the fourth row, images of answering phone provide synthetic pose examples for images of hugging.
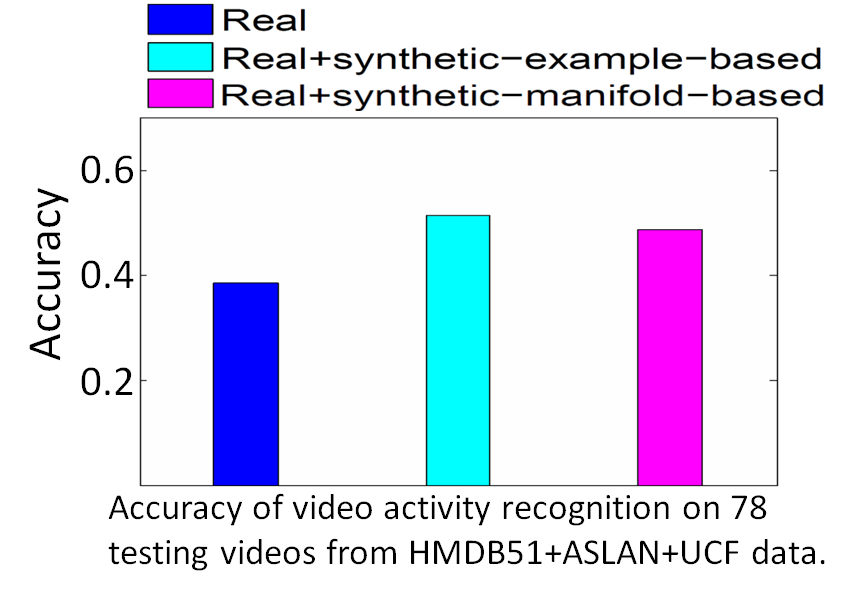
Recognizing activity in videos
- Accuracy of video activity recognition on 78 testing videos from MDB51+ASLAN+UCF data.
- Provide significant improvement in accuracy by adding our synthetic pose examples.
- Our method infers intermediate poses not covered in original snapshots.