Learning the Easy Things First: Self-Paced Visual
Category Discovery
Yong Jae Lee and
Kristen Grauman
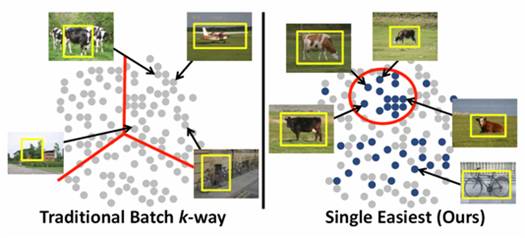
Summary
Objects
vary in their visual complexity, yet existing
discovery methods perform “batch” clustering, paying equal attention to all instances
simultaneously---regardless of the strength of their appearance or context
cues. We propose a self-paced approach
that instead focuses on the easiest
instances first, and progressively expands its repertoire to include more
complex objects. Easier regions are
defined as those with both high likelihood of generic objectness
and high confidence of surrounding familiar object context. At each cycle of the discovery process, we
re-estimate the easiness of each subwindow in the
pool of unlabeled images, and then retrieve a single prominent cluster from
among the easiest instances. Critically,
as the system gradually accumulates models, each new (more difficult) discovery
benefits from the context provided by earlier discoveries. Our experiments demonstrate the clear
advantages of self-paced discovery relative to conventional batch approaches,
including both more accurate summarization as well as stronger predictive
models for novel data.
Approach
Our
approach iterates over four main steps:
(1) Identifying the easy
instances among the image regions in U.
(2) Discovering the next
prominent group of easy regions.
(3) Training a model with
the discovered category to detect harder instances in the data, moving results
to D.
(4) Revising the
object-level context for all regions in U according to the
most recent discovery.
D : the
discovered windows that have been assigned to a cluster.
U : the
undiscovered windows that remain in the general unlabeled pool.
Ct : the set of familiar categories at
time t.
Identifying Easy
Objects
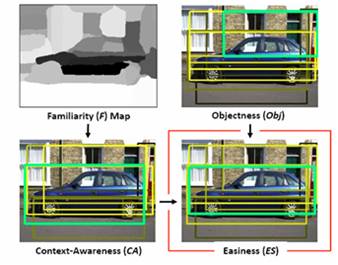

We identify the
easiest instances among U according to both low-level image
properties and the current familiar classes in C. We define an “easiness” function
![]()
that
scores a window w based on how likely it is to contain an
object (“objectness”, Obj)
and to what extent it is surrounded by familiar
objects (“context-awareness”, CA). We
compute “objectness” using the measure developed in [Alexe et al., CVPR 2010].
We compute “context-awareness” by averaging the familiarity scores
(i.e., likelihood of belonging to a familiar category) of the surrounding superpixels, giving more weight to those that are spatially
near.
The figure on the right shows randomly
selected examples among the easiest and hardest instances chosen by our
algorithm. Our method is able to bypass
the hard or noisy instances, and focus on the easiest ones first. Note that a region with high objectness can yield low easiness if its context is yet
unfamiliar (e.g., see red boxes in (b)).
Single Prominent
Category Discovery
To compute the similarity between two
windows wi
and wj, we use the
combined kernel:
![]()
Under this kernel, easy instances with both
similar appearance and context are most likely to be grouped together.
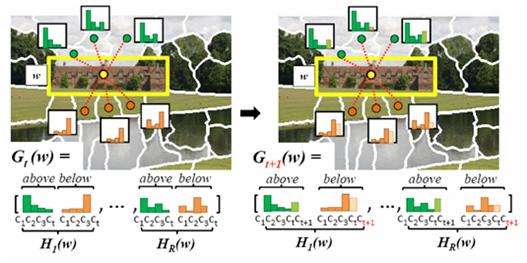
To describe appearance A,
we use color histograms, spatial pyramid bag-of-words, and pHOG. To describe context Gt
at iteration t,
we use our object-graph
descriptor [Lee and Grauman, CVPR 2010]. The descriptor expands at
each iteration to reflect the most recent discovered category.
At each iteration, we want to expand
the pool of discovered categories with a single “prominent” cluster. By seeking a single new cluster, we can
conservatively identify the most obvious new group; further, we can
incrementally refine the context model most quickly for future
discoveries. We perform complete-link
agglomerative clustering and stop merging when the distance between the most
similar (yet-unclustered) instances becomes too
large. Among these results, we select
the “best” cluster based on its silhouette coefficient and refine the selected
instances with Single-Cluster Spectral Graph Partitioning (SCSGP) [Olson et
al., RSS 2005].
Discovered Category
Knowledge Expansion
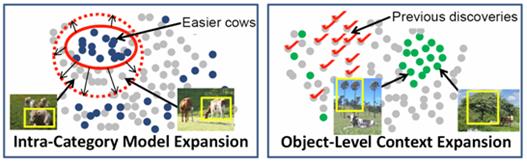
Intra-Category
Model Expansion
The
initially discovered easier instances yield a model that can be used to detect
the harder instances, which would not have clustered well due to their
appearance or different context. We use
instances in the newly discovered category to train a one-class SVM based on
their appearance representation (no context).
Then, we apply the classifier to all remaining windows in U, merge the positively classified instances
with the discovered category, and move them to D.
Object-Level
Context Expansion
The
expansion of the context model based on the discovered categories can help to
discover certain harder ones. With each
discovery, the set of familiar categories expands. Thus, for every window remaining in U, we revise its object-graph Gt to form Gt+1, augmenting it with class affinities
for the discovered category, per spatial component. This enriches the object-level context,
altering both the feature space and the easiness scores.
Iterative Discovery
Loop
Finally, having augmented Ct with
the newly discovered category, we proceed to discover the next easiest
category. Note that the easiness scores
evolve at each iteration of the discovery loop as more
objects become familiar. Further, we
loosen the “easiest” criterion over time, which gives the algorithm the
opportunity to discover harder categories in later iterations, when context
models are potentially richer. We
iterate the process until all remaining instances are too hard.
Results
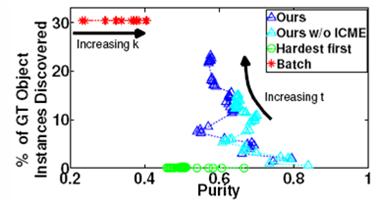
We tested our method on the MSRC-v0 dataset,
which contains 21 object classes. The
figure above shows cluster purity as a function of percentage of unique object
instances discovered. We compare our
method to a batch clustering baseline, and to a “hardest first” baseline that
focuses on the hardest instance first but otherwise follows our pipeline. Our approach produces significantly more
accurate clusters than either baseline, while selectively ignoring instances
that cannot be grouped well.
*To ensure that the batch baseline is
competitive, we give it the non-overlapping windows with the highest objectness score per image.

This figure shows examples of the discovered
categories. The numbers indicate the
iteration when that discovery was made.
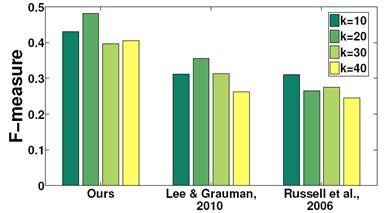
The bar plot shows comparison to [Russell et
al., CVPR 2006] and [Lee and Grauman, CVPR 2010],
which are state-of-the-art batch
discovery algorithms. By accounting for the
easiest instances first, our method summarizes the data more accurately than
either baseline.
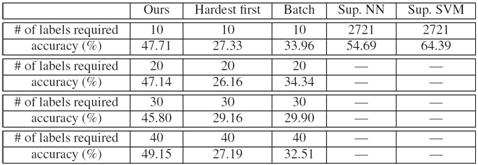
Finally, the table shows how well our
discovered categories generalize to novel images. We train one-vs-one
SVM classifiers for all discovered categories using the averaged appearance
kernels. To coarsely simulate obtaining
labels from a human annotator, we label all instances in a cluster according to
the ground-truth majority instance. In
addition to the baselines from above, we compare to two “upper bounds” in which
the ground truth labels on all instances are used to train a nearest-neighbor
(NN) and SVM classifier.
As expected, the fully supervised methods
provide the highest accuracy, yet at the cost of significant human effort (one
label per training window). On the other
hand, our method requires a small fraction of the labels (one per discovered
category), yet still achieves accuracy fairly competitive with the supervised
methods, and substantially better than either the batch or hardest-first
baselines.
Publication
Learning the Easy
Things First: Self-Paced Visual Category Discovery
[pdf]
Yong Jae Lee and Kristen Grauman
To appear, In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), Colorado Springs, CO, June 2011.