Story-Driven Summarization for Egocentric Video
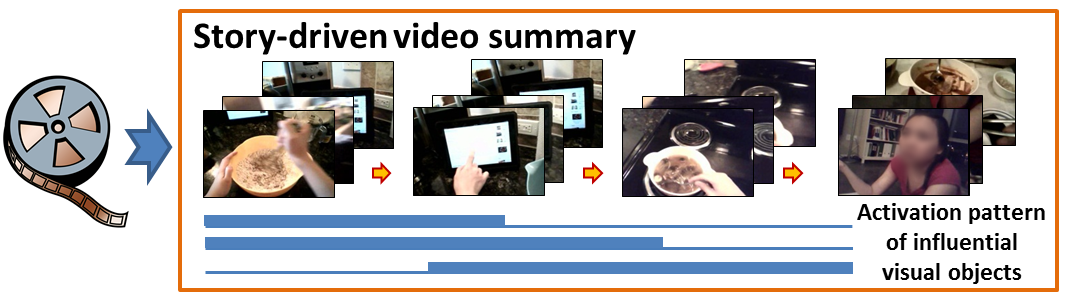
Our method generates a story-driven summary from an unedited egocentric video. A good story is defined as a coherent chain of video subshots in which each subshot influences the next through some (active) subset of influential visual objects.
Abstract
We present a video summarization approach that discovers the story of an egocentric video. Given a long input video, our method selects a short chain of video subshots depicting the essential events. Inspired by work in text analysis that links news articles over time, we define a randomwalk based metric of influence between subshots that reflects how visual objects contribute to the progression of events. Using this influence metric, we define an objective for the optimal k-subshot summary. Whereas traditional methods optimize a summary’s diversity or representativeness, ours explicitly accounts for how one sub-event “leads to” another—which, critically, captures event connectivity beyond simple object co-occurrence. As a result, our summaries provide a better sense of story. We apply our approach to over 12 hours of daily activity video taken from 23 unique camera wearers, and systematically evaluate its quality compared to multiple baselines with 34 human subjects.Approach
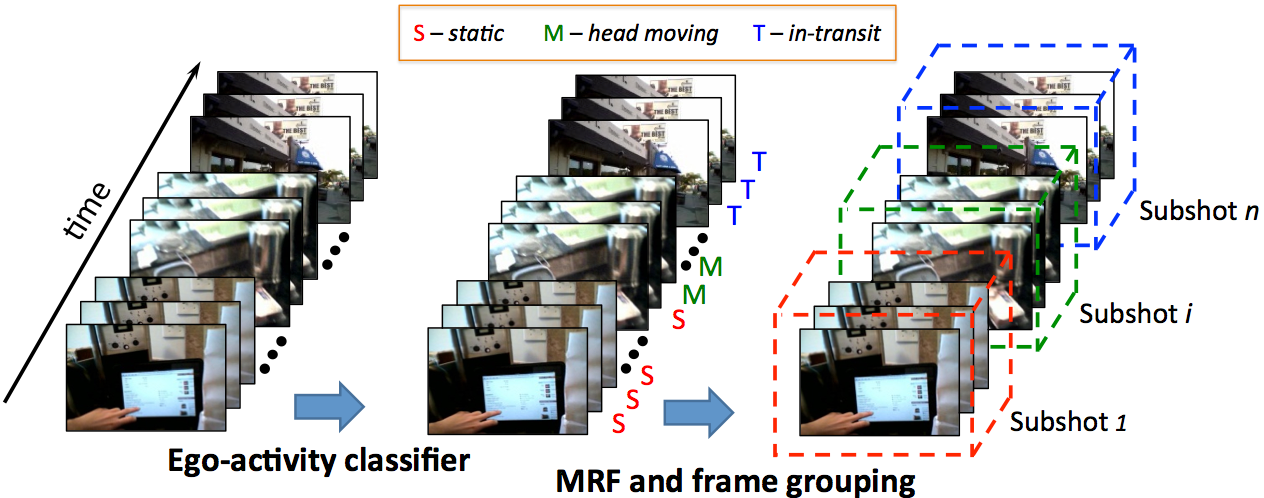
Our approach takes a long video as input and returns a short video summary as output. First, we segment the original video into a series of n subshots. For each subshot, we extract the set of objects or visual words appearing in it. Consider the subshots as nodes in a 1D chain, our goal is to select the optimal K-node chain maximizing a three-part quality objective function that reflects the story, importance, and diversity captured in the selected subshots. Finally, we compose the final summary by selecting and linking together a “chain of chains” computed from multiple broad chunks of the source video.Temporal subshot segmentation
Subshot selection objective
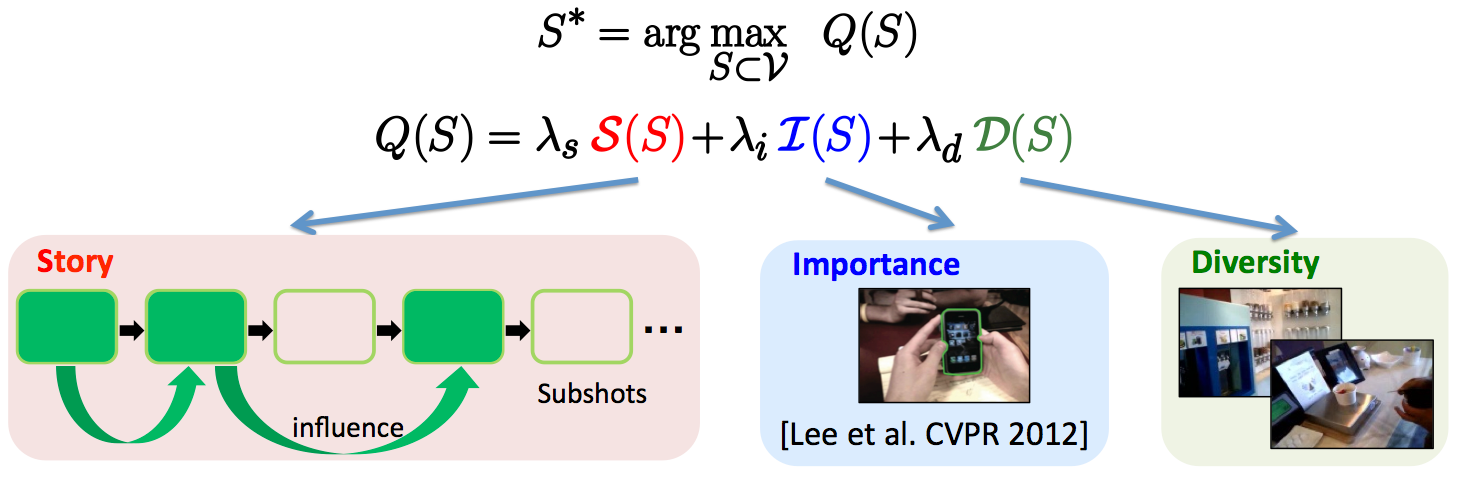
- Story: how well the chain of subshots captures the story of the input video.
- Importance: accounts for individual quality of each selected subshot as in [Lee et al. CVPR 2012].
- Diversity: enforces scene diversity in the selected chain.
Story progress between subshots

Coherent object activation patterns

Results
We use two datasets: our UT Egocentric (UTE) dataset and the Activities of Daily Living (ADL) dataset. We compare to three baselines: (1) uniform sampling: We select K subshots uniformly spaced throughout the video.(2) Shortest-path: We construct a graph where all pairs of subshots have an edge connecting them. We then select the K subshots that form the shortest path connecting the first and last subshot. (3) Object-driven: We apply the state-of-the-art egocentric summarization method [Lee et al. CVPR 2012].
We perform a “blind taste test” in which users report which summary best captures the original story. The test works as follows. We first show the users a sped-up version of the entire original video, and ask them to write down the main story events. The latter is intended to help them concentrate on the task at hand. Then, we show the subject two summaries for that original video; one is ours, one is from a baseline method. After viewing both, the subject is asked, Which summary better shows the progress of the story?

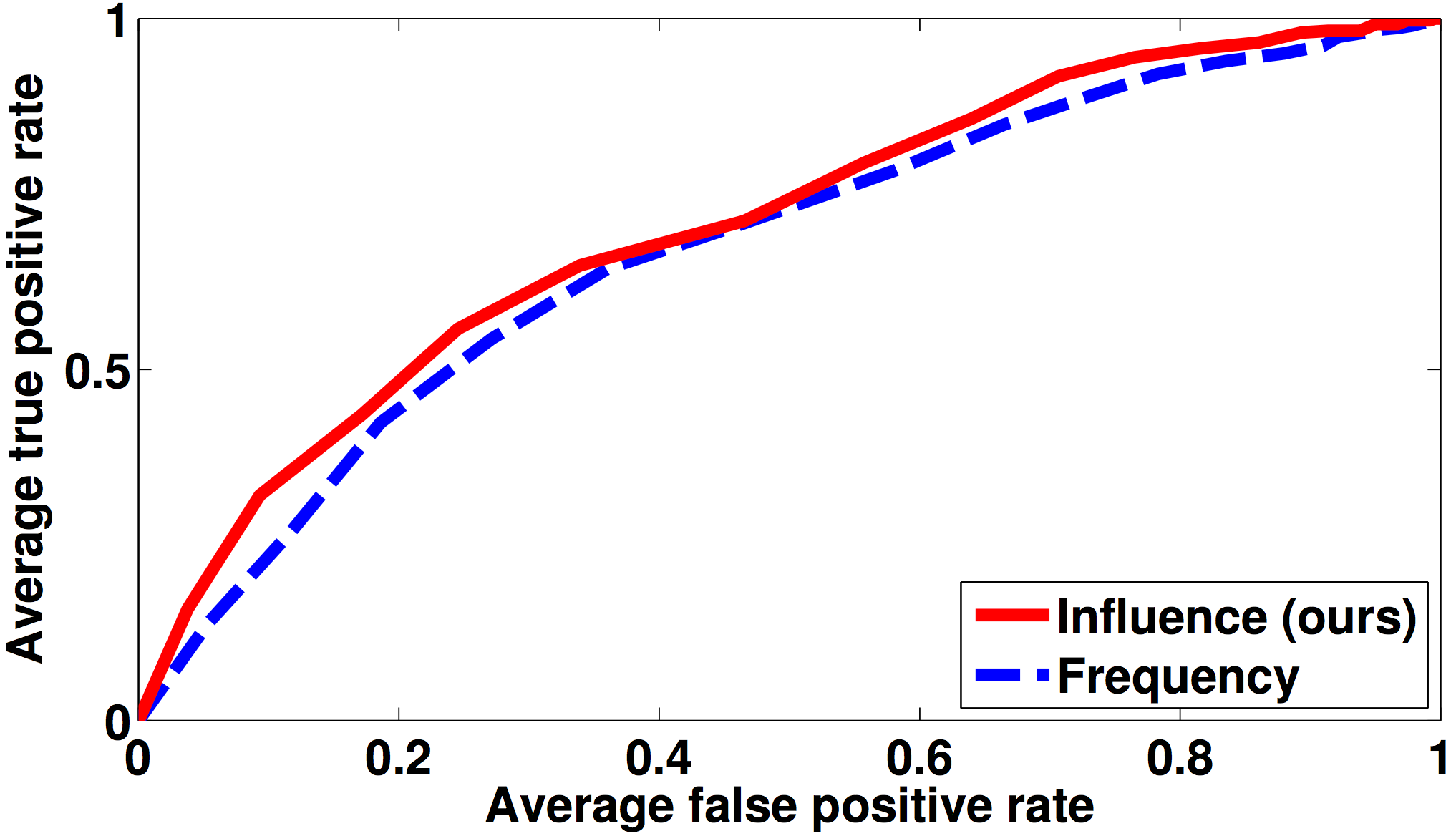
User study results. Numbers indicate percentage of users who prefer our method’s summary over each of the three baselines.
The final set shown to subjects consists of 5 hours and 11 events for UTE and 7 hours and 37 events for ADL. We enlisted 34 total subjects. They range from 18-60 years old. We show our summary paired separately with each baseline to five different users, and take a vote to robustly quantify the outcome. This makes a total of 535 tasks done by our subjects. The study amounts to about 45 hours of user time.

Example from UTE data. Our method clearly captures the progress of the story: serving ice cream leads to weighing the ice cream, which leads to watching TV in the ice cream shop, then driving home. Even when there are no obvious visual links for the story, our method captures visually distinct scenes (see last few subshots in top row). The shortest-path approach makes abrupt hops across the storyline in order to preserve subshots that smoothly transition (see redundancy in its last 5 subshots). While the object-driven method [Lee et al. CVPR 2012] does indeed find some important objects (e.g., TV, person), the summary fails to suggest the links between them.

Example from ADL data. While here uniform sampling produces a plausible result, ours appears to be more coherent. Objects such as milk and cup connect the selected keyframes and show the progress of the story—preparing a hot drink and enjoying it by the TV. Shortest-path produces the weakest result due to its redundant keyframes.
Publications
-
Story-Driven Summarization for Egocentric Video. Zheng Lu and Kristen Grauman. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, June 2013. [pdf][supp][poster][data].
- Discovering Important People and Objects for Egocentric Video Summarization. Yong Jae Lee, Joydeep Ghosh, and Kristen Grauman. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012. [pdf][project page][data].
Last modified: Sat, Jun 22, 2013.