Sudheendra Vijayanarasimhan and Kristen Grauman
Department of Computer Sciences,
University of Texas at Austin
Active learning and crowd-sourced labeling are promising ways to efficiently build up training sets for object recognition, but thus far techniques are tested in artificially controlled settings.
Specifically,
(``sandbox'' data - the vision researcher has already determined the dataset's source and scope which compromises the generality of a model learned using it)
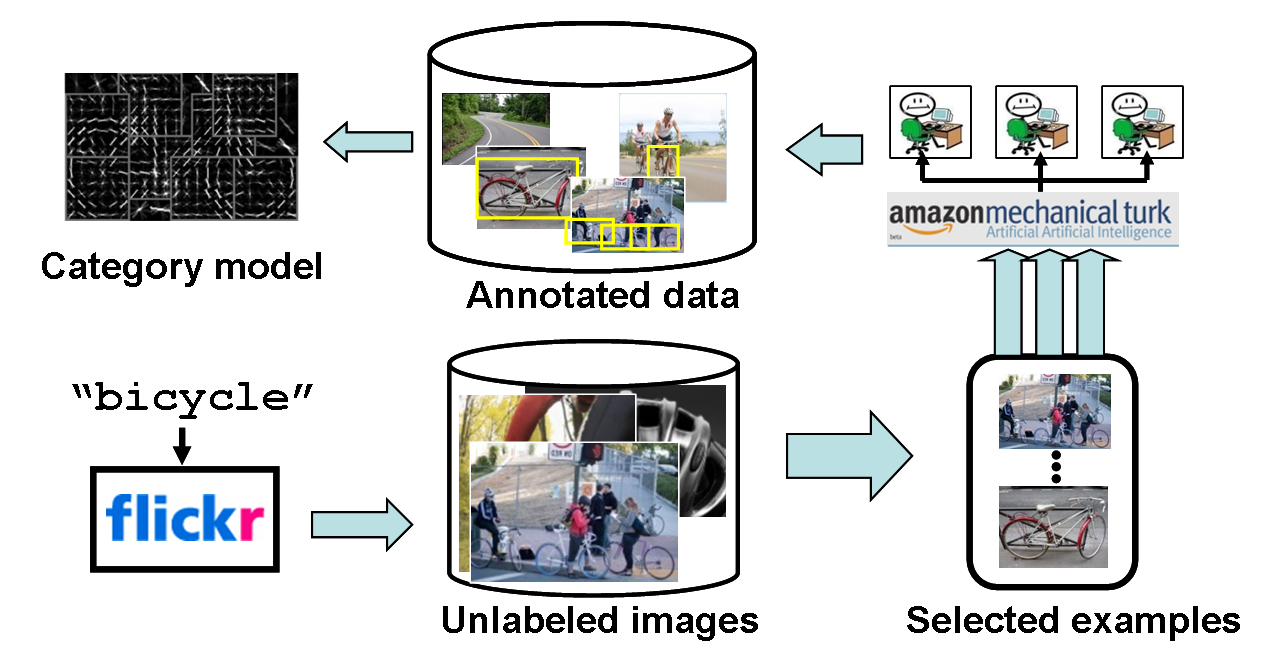
Our goal in this work is to take crowd-sourced active annotation out of the ``sandbox'' and automate object detector training.
Given just the name of category, we present an approach for ``live learning'' of detectors for that category
Rather than fill the data pool with some canned dataset, the system
Throughout the procedure we do not intervene with what goes into the system's data pool, nor the annotation quality from the hundreds of online annotators.
Large-scale active selection
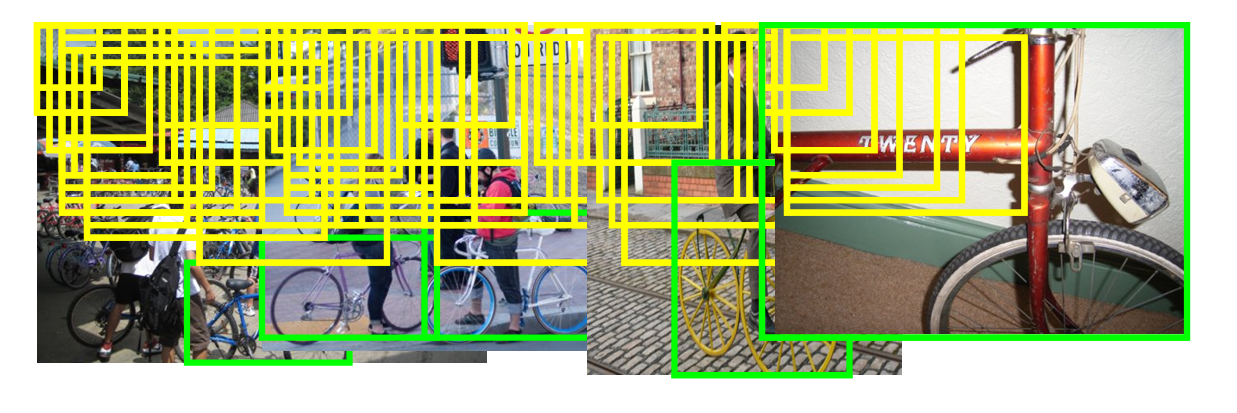
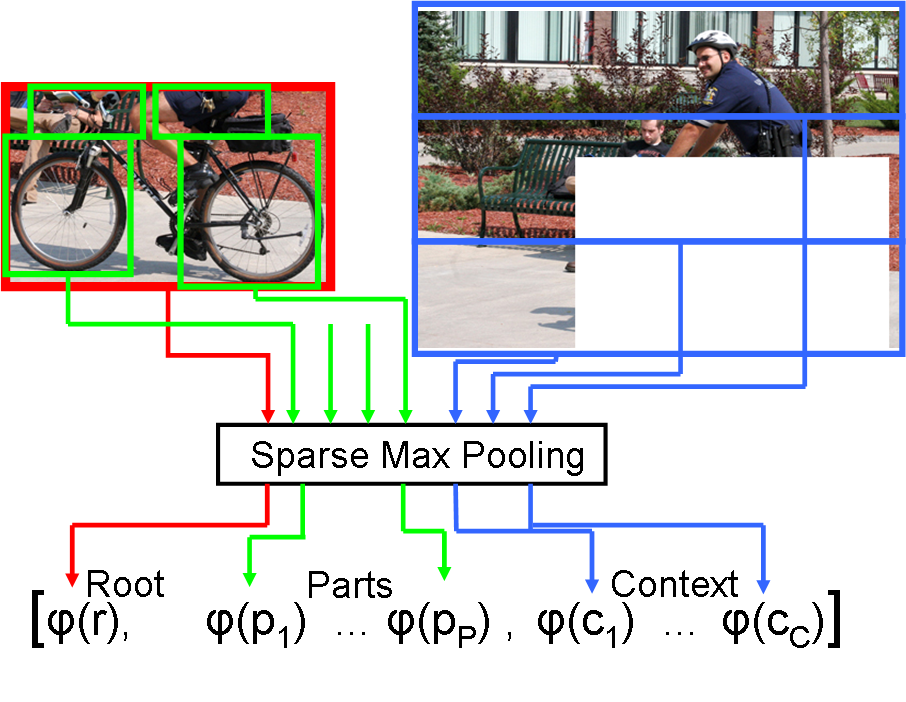
We introduce a novel partbased detector amenable to linear classifiers, and show how to identify its most uncertain instances in sub-linear time with our recently proposed hashing-based solution.
|
Linear classification
|
Candidate window generation
|
Large-scale active selection
|
Annotation collection
|
||||
|
|
|

|
||||
|
|
|
|
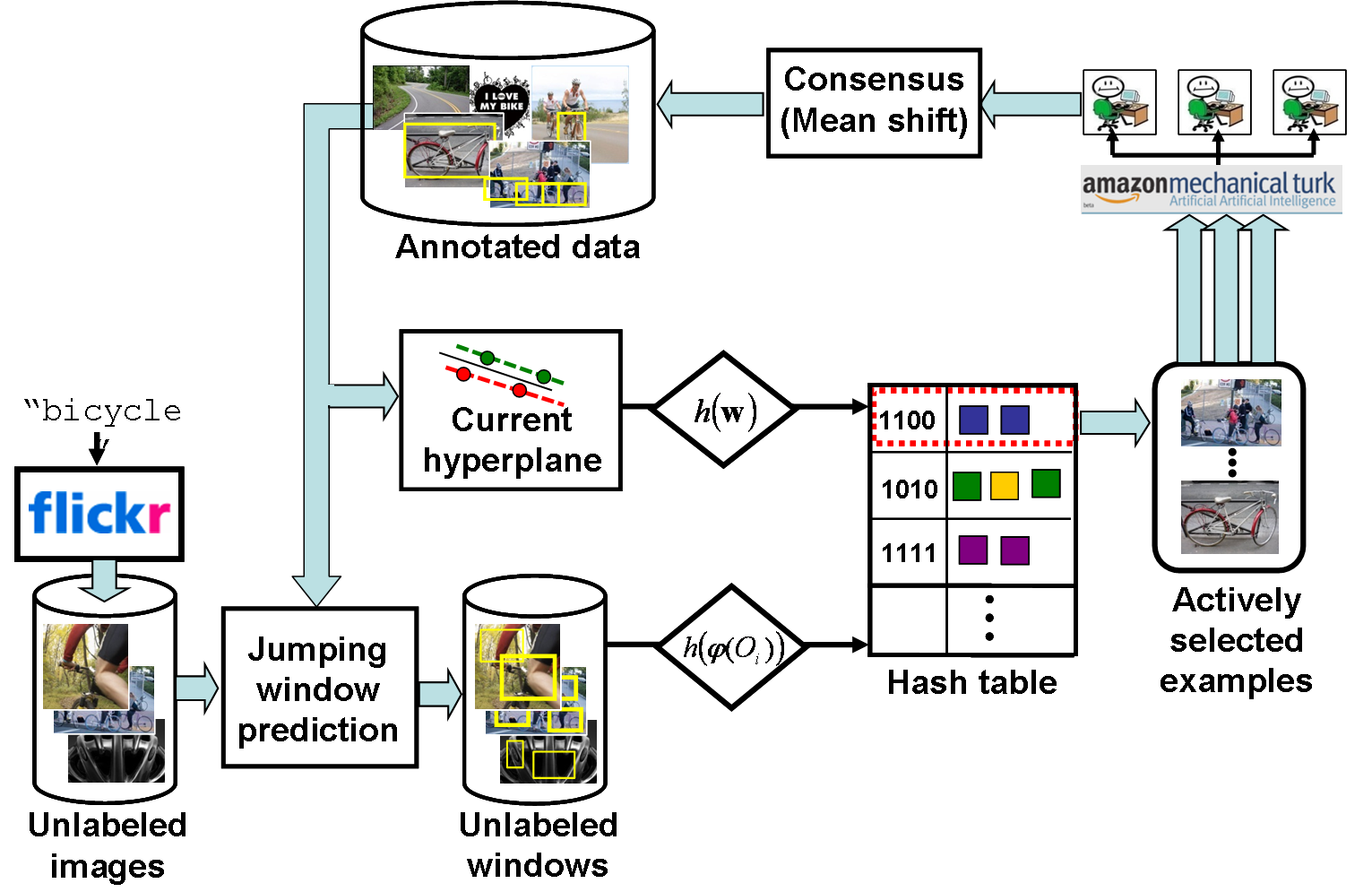
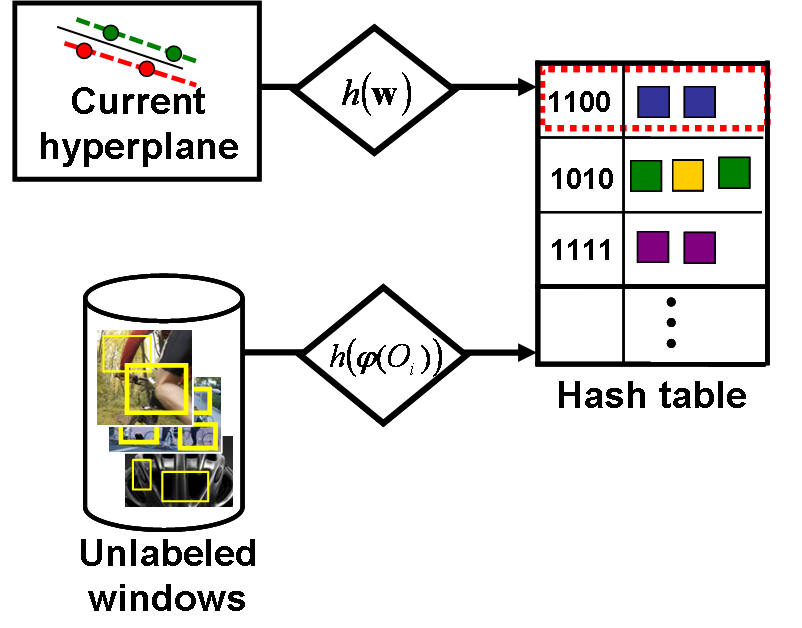
The main loop consists of using the current classifier to generate candidate jumping windows, storing all candidates in a hash table, querying the hash table using the hyperplane classifier, giving the actively selected examples to online annotators, taking their responses as new ground truth labeled data, and updating the classifier.
We evaluate our approach on both benchmark PASCAL 2007 data and by running the live learning process on Flickr.
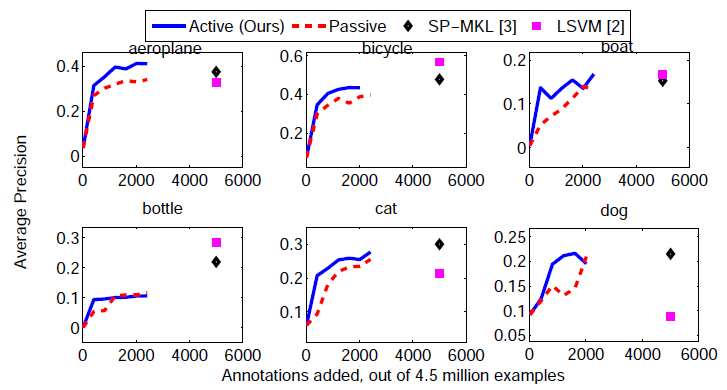
| classif | parts | feats | cands | aero. | bicyc. | bird | boat | bottl | bus | car | cat | chair | cow | dinin. | dog | horse | motor. | person | potte. | sheep | sofa | train | tvmon. | Mean | |
| Ours | linear | yes | single | jump | 48.4 | 48.3 | 14.1 | 13.6 | 15.3 | 43.9 | 49.0 | 30.7 | 11.6 | 30.3 | 13.3 | 21.8 | 43.6 | 45.0 | 18.2 | 11.1 | 28.8 | 33.0 | 47.7 | 43.0 | 30.5 |
| LSVM+HOG | nonlinear | yes | single | slide | 32.8 | 56.8 | 2.5 | 16.8 | 28.5 | 39.7 | 51.6 | 21.3 | 17.9 | 18.5 | 25.9 | 8.8 | 49.2 | 41.2 | 36.8 | 14.6 | 16.2 | 24.4 | 39.2 | 39.1 | 29.1 |
| SP+MKL | nonlinear | no | multiple | jump | 37.6 | 47.8 | 15.3 | 15.3 | 21.9 | 50.7 | 50.6 | 30.0 | 17.3 | 33.0 | 22.5 | 21.5 | 51.2 | 45.5 | 23.3 | 12.4 | 23.9 | 28.5 | 45.3 | 48.5 | 32.1 |
|
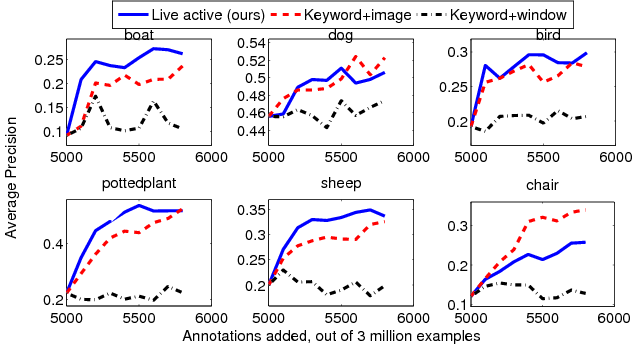
We ran the live learning process by automatically downloading example images for 6 of the most challenging categories in PASCAL by keyword search on Flickr. The system automatically obtained ground truth on actively selected images by posting on Mechanical turk.
| aeroplane | bird | boat | cat | dog | sheep | sofa | train | |
| Ours | 48.4 | 15.8* | 18.9* | 30.7 | 25.3* | 28.8 | 33.0 | 47.7 |
| Previous best | 37.6 | 15.3 | 16.8 | 30.0 | 21.5 | 23.9 | 28.5 | 45.3 |
| true positives |  |
|---|---|
| false positives |  |
| Active selection | Training | Detection per image | |
| Ours + active | 10 mins | 5 mins | 150 secs |
| Ours + passive | 0 mins | 5 mins | 150 secs |
| LSVM [2] | 3 hours | 4 hours | 2 secs |
| SP+MKL [3] | 93 hours | 67 secs |
Large-Scale Live Active Learning: Training Object Detectors with Crawled Data and Crowds,
S. Vijayanarasimhan and K. Grauman, in CVPR 2011
[paper]
Hashing Hyperplane Queries to Near Points with Applications to Large-Scale Active Learning,
P. Jain, S. Vijayanarasimhan and K. Grauman, in NIPS 2010
[paper, supplementary]