
Traditional supervised visual learning simply asks annotators "what" label an image should have. We propose an approach for image classification problems requiring subjective judgment that also asks "why", and uses that information to enrich the learned model. We develop two forms of visual annotator rationales: in the first, the annotator highlights the spatial region of interest he found most influential to the label selected, and in the second, he comments on the visual attributes that were most important. For either case, we show how to map the response to synthetic contrast examples, and then exploit an existing large-margin learning technique to refine the decision boundary accordingly. Results on multiple scene categorization and human attractiveness tasks show the promise of our approach, which can more accurately learn complex categories with the explanations behind the label choices.
The main idea is to gather visual rationales alongside traditional image labels, in order to use human insight more fully to better train a discriminative classifier. "Rationales" are a way of getting more information from a single annotation by a human annotator: we ask the annotator not only for the image's class label, but additionally for information about "why" they chose that label. The "why" part is the rationale.
We particularly target subjective, perceptual labeling tasks. We first explain the notion of contrast examples as used in prior NLP rationales work [1], and then define our two proposed forms of visual rationale.
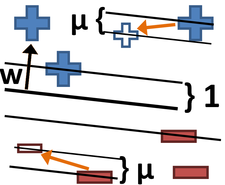
We define and use rationales in a support vector machine (SVM) based on the approach of Zaidan et al. [1]. This involves the use of rationales to form "contrast examples" (positive/negative training examples that are "less positive" or "less negative" due to the removal of the rationale). To use these contrast examples in an SVM, we introduce into the SVM an additional margin that separates positive examples from positive contrast examples, and negative examples from negative contrast examples, along with the normal SVM margin that divides positive and negative examples. See section 3.1 of our paper for details.
 |
 |
 |
| Original Example | Rationale | Contrast Example |
To form contrast examples from spatial rationales (such as the one shown in purple on the figure skater at the top of this page), we "mask out" the regions of the image that the annotator chose as a rationale. See section 3.2 of our paper for details.
 |
 |
 |
| Original Example | Rationale | Contrast Example |
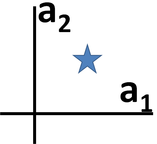
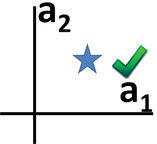
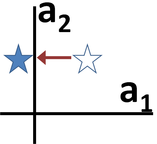
To form contrast examples from visual attribute rationales (such as those shown to the right of the figure skater at the top of this page), we weaken the magnitude of attributes chosen as a rationale (attribute a1 was chosen as the rationale in the diagram shown above, so the contrast example has less of a1).
We propose two types of visual attribute rationales - homogeneous, in which attributes are named generally as rationales for each class, and individual, in which attributes are named as rationales on a per-image basis (more analogous to the spatial rationales). See section 3.3 of our paper for details.
We explore the utility of our approach with three datasets. Central to our approach are the human annotators, who provide rationales that should give insight into their class decision for an image. We use Mechanical Turk (MTurk) to gather most of our annotations in order to create large datasets with a variety of annotation styles.
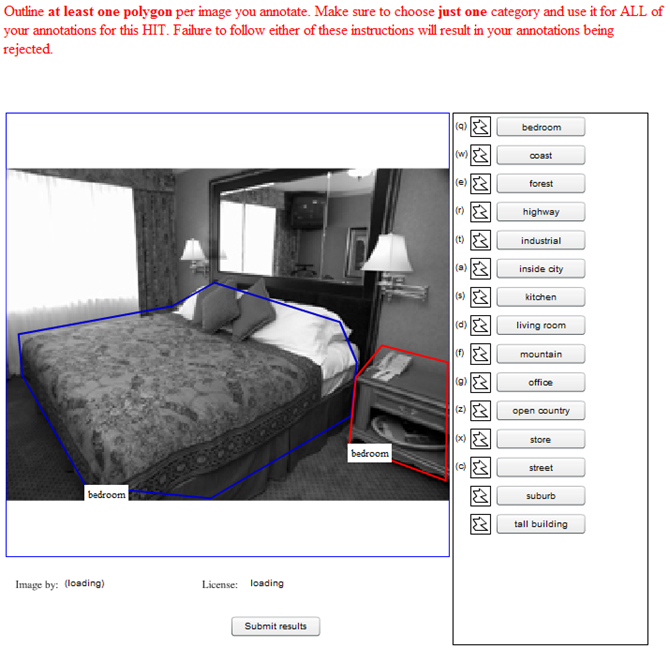
We first consider the 15 Scene Categories dataset [2], which consists of 15 indoor and outdoor scene classes, with 200-400 images per class. We select this dataset since (1) scene types often lack clear-cut semantic boundaries (e.g., "inside city" vs. "street"), requiring some thought by an annotator, and (2) scenes are loose collections of isolated objects with varying degrees of relevance, making them a good testbed for spatial rationales.
Below is an example of the MTurk interface to gather the scene categories rationales (click to enlarge):
Examples of scene categories annotations from MTurk users:

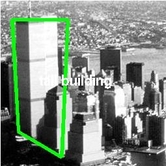
|


|


|
| Typical annotations | Tight annotations | "Artistic" annotations |
See section 4.1 of our paper for details on annotations for the scene categories task.
Our results for this task are shown below. Note that our approach beats all three of our baselines in 13 out of 15 scene categories.
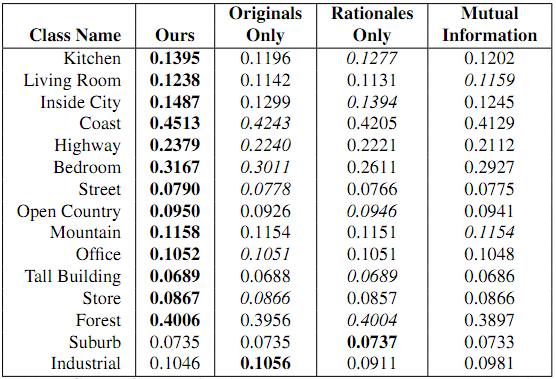
See section 5.1 of our paper for details and analysis on the baselines, experiment setup, and results for the scene categories task.
We introduce a new dataset using images from Hot or Not (hotornot.com), a once popular website where users rate images of one another for attractiveness on a 1-10 scale. We collected 1000 image/rating pairs of both men and women, requiring each to have been rated at least 100 times (for a robust "hotness" label). This dataset is an excellent testbed, since we expect rationales are valuable to better learn such subjective clasification tasks.
We annotated a subset of the image ourselves, and also had workers from MTurk annotate the entire data set. Shown below is the annotation interface used to gather annotations from MTurk (click to enlarge):

Examples of Hot or Not annotations from MTurk users:

|

|

|

|
| Hot, Male | Not, Male | Hot, Female | Not, Female |
See section 4.2 of our paper for details on annotations for the Hot or Not task.
Our results for this task are shown below. Note that, for males, our approach with our annotations beats all four of our baselines - our accuracy is higher with only 25 training examples than any baseline with 100 training examples. For females, we only beat the baselines with 100 training examples using our annotations.
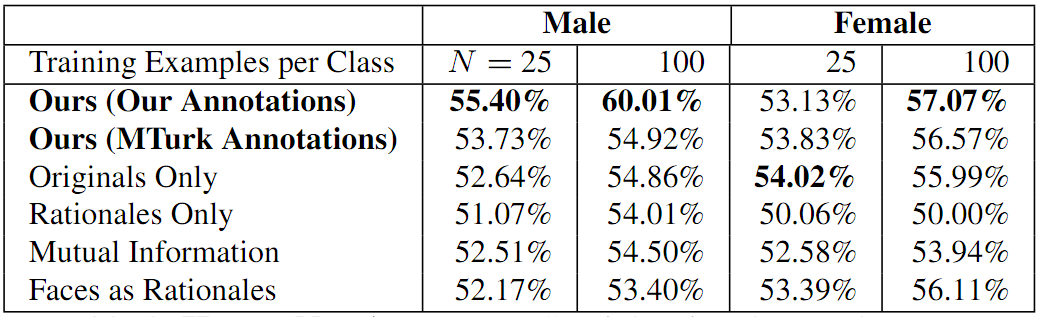
See section 5.2 of our paper for details and analysis on the baselines, experiment setup, and results for the Hot or Not task.
Finally, we consider the Public Figures dataset [3], which contains 58,797 images of 200 people, and 73 attributes. We use it to test our attribute rationales for the attractiveness test, and leverage the binary attribute classifier outputs kindly shared by the authors to define a1, ..., aV. Given that most people in the dataset are well-known public figures, we simply divided them by identity into the attractive/unattractive categories ourselves. Of the 116 men, we took 74 as attractive, 42 unattractive; of the 84 women, we took 76 as attractive and just 8 as unattractive.
For ease of explaining the slightly more complex and time-consuming task, we asked friends unfamiliar with the project to provide rationales (rather than using MTurk). Shown below is the annotation interface used to gather annotations (click to enlarge):
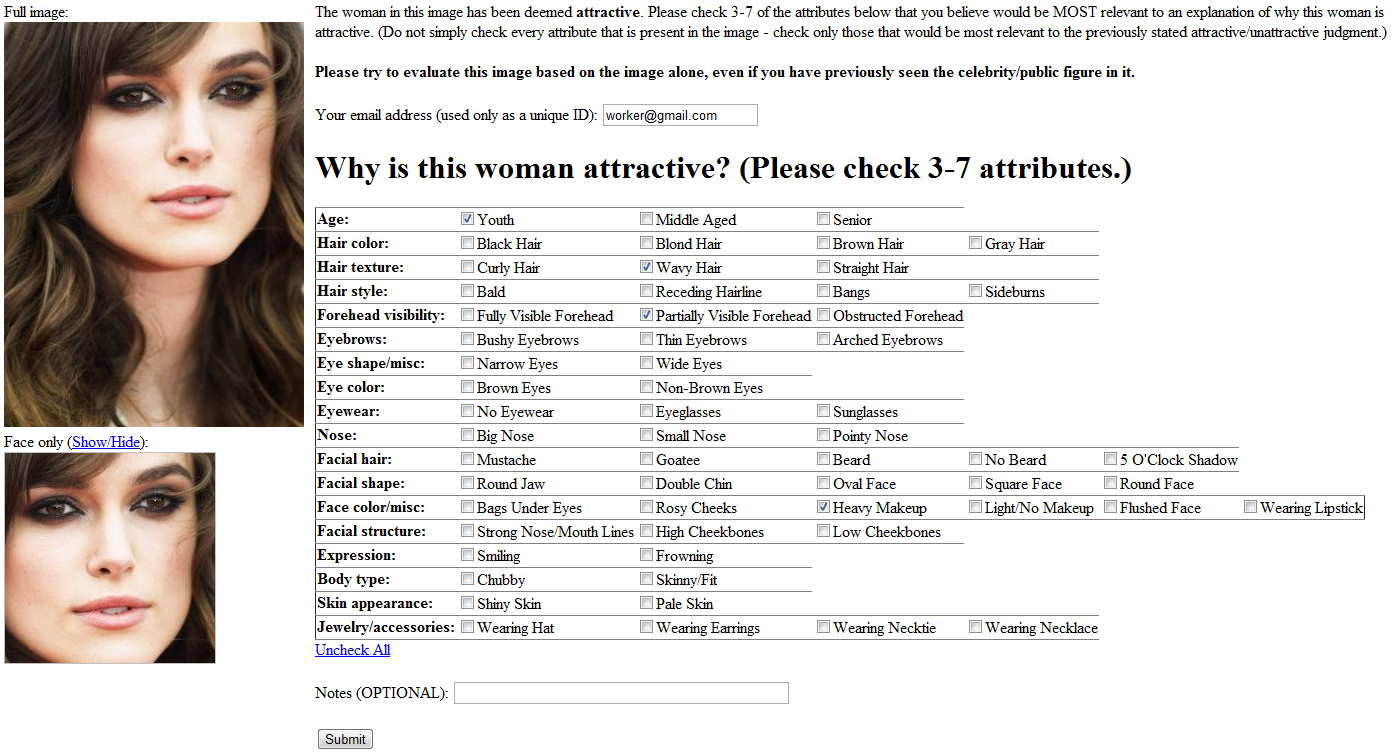
Examples of Public Figure attribute annotations from our annotators:

See section 4.3 of our paper for details on annotations for the Public Figures task.
Our results for this task are shown below. Note that, with homogeneous rationales, our accuracy is higher than the baseline for both Males and Females, and with individual rationales, our accuracy is higher than the baseline for Males.
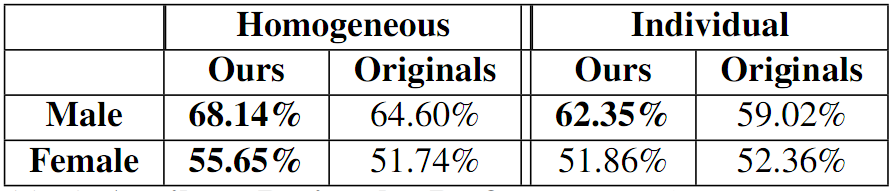
See section 5.2 of our paper for details and analysis on the experiment setup and results for the Public Figures task.
Scene Categories spatial rationale annotations (Zip file: README)
Hot or Not image and rating data (Zip file: README)
Hot or Not rationale annotations - ours (Zip file: README)
Hot or Not rationale annotations - MTurk (Zip file: README)
Public Figures attribute rationale annotations (CSV file: README)
Fifteen Scene Categories dataset [2]: http://www-cvr.ai.uiuc.edu/ponce_grp/data/
Public Figures dataset [3]: http://www.cs.columbia.edu/CAVE/databases/pubfig/
J. Donahue and K. Grauman. Annotator Rationales for Visual Recognition. To appear, Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, November 2011. [Paper] [Poster] [Video]
[1] O. Zaidan, J. Eisner, and C. Piatko. Using Annotator Rationales to Improve Machine Learning for Text Categorization. In NAACL - HLT, 2007.
[2] L. Fei-Fei and P. Perona. A Bayesian Hierarchical Model for Learning Natural Scene Categories. In CVPR, 2005.
[3] N. Kumar, A. C. Berg, P. N. Belhumeur, and S. K. Nayar. Attribute and Simile Classifier for Face Verification. In ICCV, 2009.