
Summary
We present a video summarization approach for
egocentric or "wearable" camera data. Given hours
of video, the proposed method produces a compact storyboard
summary of the camera wearer's day. In contrast to
traditional keyframe selection techniques, the resulting
summary focuses on the most important objects and people with
which the camera wearer interacts. To accomplish this,
we develop region cues indicative of high-level saliency in
egocentric video---such as the nearness to hands, gaze, and
frequency of occurrence---and learn a regressor to predict the
relative importance of any new region based on these
cues. Using these predictions and a simple form of
temporal event detection, our method selects frames for the
storyboard that reflect the key object-driven
happenings. Critically, the approach is neither
camera-wearer-specific nor object-specific; that means the
learned importance metric need not be trained for a given user
or context, and it can predict the importance of objects and
people that have never been seen previously. Our results
with 17 hours of egocentric data show the method's promise
relative to existing techniques for saliency and
summarization.
Approach
Our goal is to create a storyboard
summary of a person’s day that is driven by the important
people and objects. We define importance in the scope of
egocentric video: important
things are those with which the camera wearer has
significant interaction.
There are four main steps to our approach: (1) using novel
egocentric saliency cues to train a category independent
regression model that predicts how likely an image region
belongs to an important person or object; (2) partitioning the
video into temporal events. For each event, (3) scoring
each region’s importance using the regressor; and (4)
selecting representative key-frames for the storyboard based
on the predicted important people and objects.
Egocentric video data
collection
We use the Looxcie wearable camera,
which captures video at 15 fps at 320 x 480 resolution.
We collected 10 videos, each of 3-5 hours in length.
Four subjects wore the camera for us: one undergraduate
student, two grad students, and one office worker. The
videos capture a variety of activities such as eating,
shopping, attending a lecture, driving, and cooking.
Annotating important
regions in training video

In order to learn meaningful egocentric properties without
overfitting to any particular category, we crowd-source large
amounts of annotations using Amazon’s Mechanical Turk
(MTurk). For egocentric videos, the object must be seen
in the context of the camera wearer’s activity to properly
gauge its importance. We carefully design two annotation
tasks to capture this aspect. In the first task, we ask
workers to watch a three minute accelerated video and to
describe in text what they perceive to be essential people or
objects necessary to create a summary of the video. In
the second task, we display uniformly sampled frames from the
video and their corresponding text descriptions obtained from
the first task, and ask workers to draw polygons around any
described person or object. See the figure above for
example annotations.
Learning region importance
in egocentric video

Given a video, we first generate candidate regions for each
frame using the segmentation method of [Carreira and
Sminchisescu, CVPR 2010]. We generate roughly 800
regions per frame. For each region, we compute a set of
candidate features that could be useful to describe its
importance. Since the video is captured by an active
participant, we specifically want to exploit egocentric
properties such as whether the object/person is interacting
with the camera wearer, whether it is the focus of the
wearer’s gaze, and whether it frequently appears. The
egocentric features are shown above. In addition, we aim
to capture high-level saliency cues—such as an object’s motion
and appearance, or the likelihood of being a human face—and
generic region properties shared across categories, such as
size or location. Using all of these features, we train
a regression model that can predict a region’s
importance.
Segmenting the video into
temporal events
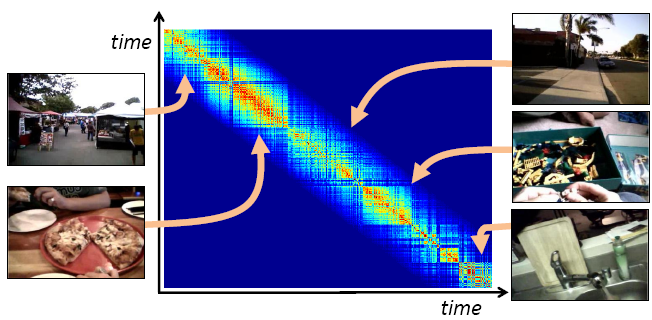
We first partition the video temporally into events. We cluster scenes in such a way that frames with similar global appearance can be grouped together even when there are a few unrelated frames (“gaps”) between them. Specifically, we perform complete-link agglomerative clustering with a distance matrix that reflects color similarity between each pair of frames weighted by temporal proximity.
Discovering an event’s key
people and objects
Given an event, we
first score each region in each frame using our
regressor. We take the highest-scored regions and group
instances of the same person or object together using a
factorization approach [Perona and Freeman, ECCV 1998].
For each group, we select the region with the highest score as
its representative. Finally, we create a storyboard
visual summary of the video. We display the event
boundaries and frames of the selected important people and
objects. We automatically adjust the compactness of the
summary with selection criteria on the region importance
scores and number of events, as we illustrate in our results.
Results
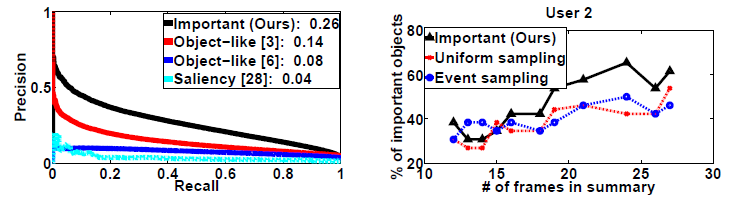
We analyze (1) the performance of our method’s important region prediction, (2) our egocentric features, and (3) the accuracy and compactness of our storyboard summaries.


User study results. Numbers indicate percentage of responses for each question, always comparing
our method to the baseline (i.e., highest values in “much better” are ideal).
Publications
Discovering Important People and Objects for Egocentric Video Summarization [pdf] [supp] [extended abstract] [poster] [data]
Yong Jae Lee, Joydeep Ghosh, and Kristen Grauman
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, June 2012.
Story-Driven Summarization for Egocentric Video [pdf] [project page] [data]
Zheng Lu and Kristen Grauman
In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, June 2013.