slides
Paper reviews for 2 papers due Monday Sept 4, then every Monday thereafter.
Invariant local features, local feature matching, instance recognition, visual vocabularies and bag-of-words, large-scale mining

image credit: Andrea Vedaldi and Andrew Zisserman
« Video Google: A Text Retrieval Approach to Object Matching in Videos, Sivic and Zisserman, ICCV 2003. [pdf] [demo]
« Local Invariant Feature Detectors: A Survey,
Tuytelaars and Mikolajczyk. Foundations and Trends
in Computer Graphics and Vision, 2008. [pdf]
[Oxford
code] [Selected
pages -- read pp. 178-188, 216-220, 254-255]
For more background on feature extraction: Szeliski book: Sec 3.2 Linear filtering, 4.1 Points and patches, 4.2 Edges
SIFT meets CNN: A Decade Survey of Instance Retrieval. L. Zheng, Y. Yang, Q. Tian. [pdf]Object Retrieval with Large Vocabularies and Fast Spatial Matching. Philbin, J. and Chum, O. and Isard, M. and Sivic, J. and Zisserman, A. CVPR 2007 [pdf]
Scale-space theory: A basic tool for analysing structures at di fferent scales. T. Lindeberg. 1994 [pdf]
Andrea Vedaldi's VLFeat code, including SIFT, MSER, hierarchical k-means.
INRIA LEAR team's software, including interest points, shape features
FLANN - Fast Library for Approximate Nearest Neighbors. Marius Muja et al.
Code for downloading Flickr images, by James Hays
UW Community Photo Collections homepage
INRIA Holiday images dataset
NUS-WIDE tagged image dataset of 269K images
MIRFlickr dataset
Dataset index
Image and object recognition. Image descriptors, classifiers, support vector machines, nearest neighbors, convolutional neural networks, large-scale image collections; Image recognition, object detection, semantic segmentation, instance segmentation.

Image credit: ImageNet
« You Only Look Once: Unified, Real-Time Object Detection. J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. CVPR 2016. [pdf] [project/code]
« Deep Residual Learning for Image Recognition Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun, CVPR 2016. [pdf] [code] [talk] [slides]
« Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories, Lazebnik, Schmid, and Ponce, CVPR 2006. [pdf] [15 scenes dataset] [libpmk] [Matlab]
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs Chen, Papandreou, Kokkinos, Murphy, Yuille. ICLR 2015. [pdf] [code/data]
ImageNet Classification with Deep Convolutional Neural Networks. A. Krizhevsky, I. Sutskever, and G. Hinton. NIPS 2012 [pdf]
Very Deep Convolutional Networks for Large-scale Image Recognition. K. Simonyan and A. Zisserman, ICLR 2015 [pdf]
Deep Learning. Y. LeCun, Y. Bengio, G. Hinton. Nature, 2015. [pdf]
YOLO9000: Better, Faster, Stronger. J. Redmon and A. Farhadi. CVPR 2017 [pdf] [code]
Microsoft COCO: Common Objects in Context. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, C. Lawrence Zitnick, ECCV 2014. [pdf]
SSD: Single Shot MultiBox Detector. W. Liu et al. ECCV 2016. [pdf] [code] [slides] [video]
Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. R. Girshick, J. Donahue, T. Darrell, J. Malik. CVPR 2013 [pdf] [supp] (see also fast R-CNN, and faster R-CNN)
Mask R-CNN. K. He, G. Gkioxari, P. Dollar, R. Girshick. ICCV 2017. [pdf]
Focal Loss for Dense Object Detection. T-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar. ICCV 2017. [pdf] [code]
A Discriminatively Trained, Multiscale, Deformable Part Model, by P. Felzenszwalb, D. McAllester and D. Ramanan. CVPR 2008. [pdf] [code]
Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, T. Darrell. CVPR 2015. [pdf] [models]
Hypercolumns for Object Segmentation and Fine-Grained Localization. B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. CVPR 2015 [pdf] [code]
Benchmarking State-of-the-Art Deep
Learning Software Tools. S. Shi, Q. Wang, P. Xu,
X. Chu. 2016. [pdf]
Practical tips:
CNN resources
VGG Net
Humans vs. CNNs on ImageNet
Scenes - PlaceNet
VLFeat code
LIBPMK feature extraction code, includes dense sampling
LIBSVM library for support vector machines
PASCAL VOC Visual Object Classes Challenge
Deep learning portal, with Theano tutorials
Colah's blog
Deep learning blog
iPython notebook for Caffe
Tips for Caffe OS X El Capitan
Open Images Dataset - 9M images with labels and bounding boxes
Selective search region proposals
Fast SLIC superpixels
Greg Mori's superpixel code
Berkeley Segmentation Dataset and code
Pedro Felzenszwalb's graph-based segmentation code
Mean-shift: a Robust Approach Towards Feature Space Analysis [pdf] [code, Matlab interface by Shai Bagon]
David Blei's Topic modeling code
Berkeley 3D object dataset (kinect)
Labelme Database
Scene Understanding Symposium
PASCAL VOC Visual Object Classes Challenge
Hoggles
Dataset index
ConvNets for Visual Recognition course, Andrej Karpathy, Stanford
Machine learning with neural nets lecture, Geoffrey Hinton
Deep learning course, Bhiksha Raj, CMU
Deep learning in neural networks: an overview, Juergen Schmidhuber.
slides
Unsupervised feature learning from "free" side information (tracks in video, spatial layout in images, multi-modal sensed data, ego-motion, color channels, video sequences,...) and understanding what has been learned by a given representation.

Image credit: Jing Wang et al.
« Look, Listen, and Learn. R. Arandjelovic and A. Zisserman. 2017. [pdf]
« Network Dissection: Quantifying Interpretability of Deep Visual Representations. D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba. CVPR 2017. [pdf] [code/slides]
¤ The Curious Robot: Learning Visual Representations via Physical Interactions. L. Pinto, D. Gandhi, Y. Han, Y-L. Park, and A. Gupta. ECCV 2016. [pdf] [web]
¤ Learning Representations for Automatic Colorization. G. Larsson, M. Maire, and G. Shakhnarovich. ECCV 2016. [pdf] [web] [code] [demo]
¤ Shuffle and Learn: Unsupervised Learning Using Temporal Order Verification. I. Misra, L. Zitnick, M. Hebert. ECCV 2016. [pdf] [code/models]
Learning Image Representations Tied to Ego-motion. D. Jayaraman and K. Grauman. ICCV 2015. [pdf] [web] [slides] [data] [models] [IJCV 2017]
Colorization as a Proxy Task for Visual Understanding. G. Larsson, M. Maire, G. Shakhnarovich. CVPR 2017. [pdf] [code/models]
Learning Features by Watching Objects Move. D. Pathak, R. Girshick, P. Dollar, T. Darrell, B. Hariharan. CVPR 2017. [pdf] [code]
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. R. Zhang, P. Isola, A. Efros. CVPR 2017. [pdf] [code]
Unsupervised Visual Representation Learning by Context Prediction. Carl Doersch, Abhinav Gupta, Alexei Efros. ICCV 2015. [pdf] [web] [code]
Ambient Sound Provides Supervision for Visual Learning. A. Owens, J. Wu, J. McDermottt, W. Freeman, A. Torralba. ECCV 2016. [pdf]
Visually Indicated Sounds. A. Owens, P. Isola, J. McDermott, A. Torralba, E. Adelson, W. Freeman. CVPR 2016. [pdf] [web/data]
Colorful Image Colorization. R. Zhang, P. Isola, and A. Efros. ECCV 2016. [pdf] [code/slides] [demo]
Unsupervised Learning for Physical Interaction through Video Prediction. C. Finn, I. Goodfellow, S. Levine. NIPS 2016. [pdf] [video/data/code]
Unsupervised learning of visual representations using videos. X. Wang and A. Gupta. ICCV 2015. [pdf] [code] [web]
Slow and Steady Feature Analysis: Higher Order Temporal Coherence in Video. D. Jayaraman and K. Grauman. CVPR 2016. [pdf]
Object-Centric Representation Learning from Unlabeled Videos. R. Gao, D. Jayaraman, and K. Grauman. ACCV 2016. [pdf]
Learning to See by Moving. P. Agrawal, J. Carreira, J. Malik. ICCV 2015. [pdf]
Unsupervised learning of visual representations by solving jigsaw puzzles. M. Noroozi and P. Favaro. 2016 [pdf]
Curiosity-driven Exploration by Self-supervised Prediction. D. Pathak, P. Agrawal, A. Efros, T. Darrell. ICML 2017. [pdf] [code]
External papers
Experiment (with partner)
- Thomas
- Wonjoon
Proponent/opponent:
- Rolando
- Darshan
- Xingyi
- Santhosh
- Arjun
- Chia-Wen
Detecting activities, actions, and events in images or video. Extracting foreground objects with video object segmentation. Recognition, relating actions to scenes, video descriptors, interactions with objects.

Image credit: Limin Wang
« HICO:
A Benchmark for Recognizing Human-Object
Interactions in Images. Y-W. Chao, Z. Wang,
Y. He, J. Wang, J. Deng. ICCV 2015. [pdf]
[data]
« Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, L. Van Gool. ECCV 2016. [pdf] [code]
« Unsupervised
Learning from Narrated Instruction Videos.
J. Alayrac, P. Bojanowski, N. Agrawal, J. Sivic,
I. Laptev, S. Lacoste-Julien. CVPR
2016. [pdf]
[code/video/slides]
¤ Learning to Segment Moving Objects in Videos. K. Fragkiadaki, P. Arbelaez, P. Felsen, J. Malik. CVPR 2015 [pdf] [code]
¤ Action
Recognition with Improved Trajectories. H.
Wang and C. Schmid. ICCV 2013. [pdf]
[web/code]
[IJCV]
Dynamic
Image Networks for Action Recognition. H. Bilen,
B. Fernando, E. Gavves, A. Vedaldi, S. Gould.
CVPR 2016. [pdf]
[code]
Actions~Transformations.
X. Wang, A. Farhadi, and A. Gupta. CVPR
2016. [pdf]
[data]
Modeling
actions through state changes. A Fathi and J
Rehg. CVPR 2013. [pdf]
Convolutional
Two-Stream Network Fusion for Video Action
Recognition. C. Feichtenhofer, A. Pinz, A.
Zisserman. CVPR 2016. [pdf]
[code]
FusionSeg: Learning to Combine Motion and Appearance for Fully Automatic Segmentation of Generic Objects in Video. S. Jain, B. Xiong, and K. Grauman. CVPR 2017. [pdf] [demo][project page/videos/code] [DAVIS results leaderboard]
Track and Segment: An Iterative Unsupervised Approach for Video Object Proposals. F. Xiao and Y. J. Lee. CVPR 2016. [project page] [pdf]Learning Video Object Segmentation with Visual Memory. P. Tokmakov, K. Alahari, C. Schmid. ICCV 2017. [pdf]
Fast Temporal Activity Proposals for Efficient Detection of Human Actions in Untrimmed Videos. F. Heilbron, J. Niebles, and B. Ghanem. CVPR 2016. [pdf] [web] [code]
Learning Motion Patterns in Video. P. Tokmakov, K. Alahari, C. Schmid. CVPR 2017. [pdf]
Anticipating Visual Representations from Unlabeled
Video. C. Vondrick, H. Pirsiavash, and A.
Torralba. CVPR 2016. [pdf]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. J. Carreira and A. Zisserman. CVPR 2017. [pdf] [pretrained models]
Situation
Recognition: Visual Semantic Role Labeling for Image
Understanding. M. Yatskar, L. Zettlemoyer, and
A. Farhadi. [pdf]
[demo/data/code]
Learnable Pooling with
Context Gating for Video Classification. A.
Miech, I. Laptev, J. Sivic. CVPR YouTube-8M
Workshop 2017 [pdf]
Two-stream convolutional networks for
action recognition in videos. Simonyan, K.,
Zisserman, A. NIPS 2014. [pdf]
[code]
The Open World of Micro-Videos. P.
Nguyen, G. Rogez, C. Fowlkes, and D. Ramanan.
2016 [pdf]
Learning
Spatiotemporal Features with 3D Convolutional
Networks. D. Tran, L. Bourdev, R. Fergus, L.
Torresani, and M. Paluri. ICCV 2015. [pdf]
[code]
Learning
Video Object Segmentation from Static Images. A.
Khoreva, F. Perazzi, R. Benenson, B. Schiele, A.
Sorkine-Hornung. CVPR 2017. [pdf]
One-Shot
Video Object Segmentation. S. Caelles et al. CVPR
2017. [pdf]
Structural-RNN:
Deep Learning on Spatio-Temporal Graphs. A.
Jain, A. Zamir, S. Savarese, A. Saxena. CVPR
2016 [pdf]
[code/demo]
Efficient Hierarchical Graph-Based
Video Segmentation. M. Grundmann, V.
Kwatra, M. Han, and I. Essa. CVPR
2010. [pdf]
[code,demo]
Supervoxel-Consistent Foreground
Propagation in Video. S.
Jain and K. Grauman. ECCV
2014. [pdf]
[project
page]
[data]
Temporal
Action Localization in Untrimmed Videos via Multi-stage
CNNs. Z. Shou, D. Wang, and S-F. Chang. CVPR
2016. [pdf]
[code]
Efficient
Activity Detection in Untrimmed Video with Max-Subgraph
Search. C-Y. Chen and K. Grauman. PAMI
2016. [pdf]
[web]
[code]
Hollywood
in Homes: Crowdsourcing Data Collection for Activity
Understanding. G. Sigurdsson, G. Varol, X. Wang,
A. Farhadi, I. Laptev, and A. Gupta. ECCV
2016. [pdf] [web/data]
Leaving Some Stones Unturned: Dynamic Feature Prioritization for Activity Detection in Streaming Video. Y-C. Su and K. Grauman. ECCV 2016. [pdf]
End-to-end
learning of action detection from frame glimpses in
videos. Yeung, S., Russakovsky, O., Mori,
G., Fei-Fei, L. CVPR 2016. [pdf]
[web]
What do
15,000 object categories tell us about classifying and
localizing actions? Jain, M., van Gemert, J.C.,
Snoek, C.G.M. CVPR 2015. [pdf]
Chao-Yeh Chen's compiled list of activity datasets
UCF-101 dataset
Olympic sports dataset
Charades/Hollywood in Homes dataset and challenge
Activitynet and CVPR17 workshop challenge
THUMOS action detection dataset
Kinetics YouTube dataset and paper
YouTube 8M and CVPR17 workshop challenge
Google AVA dataset of atomic actions in movies and paper
Experiments (with partner)
- Chia-Chen
- Chia-Wen
Proponent/opponent:
- Hsin-Ping
- Yu-Chuan
- Ginevra
- Wonjoon
- Shubham
- Kapil
Egocentric wearable cameras. Recognizing actions and manipulated objects, predicting gaze, discovering patterns and anomalies, temporal segmentation, forecasting future activity, longitudinal visual observations.

Image credit: D. Damen et al.
« First-Person Activity Forecasting with Online Inverse Reinforcement Learning. N. Rhinehart and K. Kitani. ICCV 2017. [pdf] [video]
« You-Do, I-Learn: Discovering Task Relevant Objects and their Modes of Interaction from Multi-User Egocentric Video. D Damen, T. Leelasawassuk, O Haines, A Calway, W Mayol-Cuevas. BMVC 2014. [pdf] [data]
« An Egocentric Perspective on Active Vision and Visual Object Learning in Toddlers. S. Bambach, D. Crandall, L. Smith, C. Yu. ICDL 2017. [pdf]
¤ KrishnaCam: Using a Longitudinal, Single-Person, Egocentric Dataset for Scene Understanding Tasks. K. Singh, K. Fatahalian, and A. Efros. WACV 2016 [pdf] [web/data]
¤ Deep Future Gaze: Gaze Anticipation on Egocentric Videos Using Adversarial Networks. M. Zhang et al. CVPR 2017. [pdf] [code/data/video]
¤ Temporal Segmentation of Egocentric Videos. Y. Poleg, C. Arora, and S. Peleg. CVPR 2014. [pdf] [code/data]
Delving into Egocentric Actions, Y. Li, Z. Ye, and J. Rehg. CVPR 2015. [pdf]
An Egocentric Look at Video Photographer Identity, Y. Hoshen and S. Peleg. CVPR 2016. [pdf]
EgoSampling: Wide View Hyperlapse from Single and Multiple Egocentric Videos. T. Halperin, Y. Poleg, C. Arora, and S. Peleg. 2017 [pdf]
Egocentric Field-of-View Localization Using First-Person Point-of-View Devices. V. Bettadapura, I. Essa, C. Pantofaru. WACV 2015. [video] [pdf]
Unsupervised Learning of Important Objects from First-Person Videos. G. Bertasius, H. S. Park, S. Yu, and J. Shi. ICCV 2017. [pdf]
How Everyday Visual Experience Prepares the Way for Learning Object Names. E. Clerkin, E. Hart, J. Rehg, C. Yu, L. Smith. ICDL 2016 [pdf]
Active Viewing in Toddlers Facilitates Visual Object Learning: An Egocentric Vision Approach. S. Bambach, D. Crandall, L. Smith, C. Yu. CogSci 2016. [pdf]
Seeing Invisible Poses: Estimating 3D Body Pose from Egocentric Video. H. Jiang and K. Grauman. CVPR 2017. [pdf] [videos]
Detecting Engagement in Egocentric Video. Y-C. Su and K. Grauman. ECCV 2016. [pdf] [data]
Story-driven Summarization for Egocentric Video. Z. Lu and K. Grauman. CVPR 2013 [pdf]
Predicting Important Objects for Egocentric Video Summarization. Y. J. Lee and K. Grauman. IJCV 2015 [pdf] [web]
Force from Motion: Decoding Physical Sensation from a First Person Video. H.S. Park, J-J. Hwang and J. Shi. CVPR 2016. [pdf] [web/data]
Learning to Predict Gaze in Egocentric Video. Y. Li, A. Fathi, and J. Rehg. ICCV 2013. [pdf] [data]
Identifying First-Person Camera Wearers in Third-Person Videos. C. Fan, J. Lee, M. Xu, K. Singh, Y. J. Lee, D. Crandall, M. Ryoo. CVPR 2017. [pdf]
Trespassing the Boundaries: Labelling Temporal Bounds for Object INteractions in Egocentric Video. ICCV 2017. [pdf] [web/data]
Visual Motif Discovery via First-Person Vision. R. Yonetani, K. Kitani, and Y. Sato. ECCV 2016. [pdf]
Learning Action Maps of Large Environments via First-Person Vision. N. Rhinehart, K. Kitani. CVPR 2016. [pdf] [slides]
Fast Unsupervised Ego-Action Learning for First-person Sports Videos. Kris M. Kitani, Takahiro Okabe, Yoichi Sato, and Akihiro Sugimoto. CVPR 2011 [pdf]
Egocentric Future Localization. H. S. Park, J-J. Hwang, Y. Niu, and J. Shi. CVPR 2016. [pdf] [web]
Figure-Ground Segmentation Improves Handled Object Recognition in Egocentric Video. X. Ren and C. Gu, CVPR 2010. [pdf] [video] [dataset]
Compact CNN for Indexing Egocentric Videos. Y. Poleg, A. Ephrat, S. Peleg, C. Arora. WACV 2015 [pdf]
Understanding Everyday Hands in Action from RGB-D Images. G. Rogez, J. Supancic, D. Ramanan. ICCV 2015. [pdf]
Recognizing Activities of Daily Living with a Wrist-mounted Camera. K. Ohnishi, A. Kanehira, A. Kanezaki, and T. Harada. CVPR 2016. [pdf] [poster] [data]
PlaceAvoider: Steering First-Person Cameras away from Sensitive Spaces. R. Templeman, M. Korayem, D. Crandall, and A. Kapadia. NDSS 2014. [pdf]
Enhancing Lifelogging Privacy by Detecting Screens. M. Korayem, R. Templeman, D. Chen, D. Crandall, and A. Kapadia. CHI 2016. [pdf] [web]
EgoSampling: Fast Forward and Stereo for Egocentric Videos. Y. Poleg, T. Halperin, C. Arora, S. Peleg. CVPR 2015. [pdf]
ECCV 2016 EPIC workshop
CVPR 2016 tutorial on first-person vision
Bristol Egocentric Object Interactions Dataset
UT Egocentric Dataset
Intel Egocentric Vison dataset
Georgia Tech Egocentric Activity datasets
GTEA Gaze
Ego-surfing dataset
CMU Multi-Modal Activity Database (kitchen)
Detecting Activities of Daily Living (ADL) dataset
Walk to Work dataset for novelty detection
JPL First-Person Interaction dataset
Multimodal Egocentric Activity Dataset - lifelogging
EgoGroup group activities dataset
UI EgoHands dataset
CMU Zoombie dataset walking with hands
GUN 71 grasps dataset
Object search dataset
UT Egocentric Engagement dataset
Wrist-mounted camera dataset
Stanford ECM dataset
EgoSurf dataset
Egocentric Shopping Cart Localization dataset
Experiments (with partner)
Proponent/opponent:
- Yajie
- Angela
- Thomas
- Kapil
Vision and action. Learning how to move for recognition, manipulation, sequential tasks. 3D objects and the next best view. Active selection of next observations for cost-sensitive recognition. Visual learning grounded in action and physical interaction. Vision/recognition for robotics.
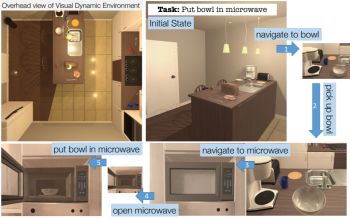
Image credit: Y. Zhu et al.
« Visual Semantic Planning Using Deep Successor Representations. Y. Zhu, D. Gordon, E. Kolve, D. Fox, L. Fei-Fei, A. Gupta, R. Mottaghi, A. Farhadi. ICCV 2017 [pdf] [web] [THOR]
« A Dataset for Developing and Benchmarking Active Vision. P. Ammirato, P. Poirson, E. Park, J. Kosecka, A. Berg. ICRA 2017. [pdf] [dataset]
« Generalizing Vision-Based Robotic Skills using Weakly Labeled Images. A. Singh, L. Yang, S. Levine. ICCV 2017. [pdf] [video] [web]
¤ The Development of Embodied Cognition: Six Lessons from Babies. L. Smith and M. Gasser. Artif Life. 2005 [pdf]
¤ Deep Affordance-grounded Sensorimotor Object Recognition. S. Thermos et al. CVPR 2017. [pdf]
¤ Curiosity-Driven Exploration by Self-Supervised Prediction. D. Pathak, P. Agrawal, A. Efros, T. Darrell. ICML 2017. [pdf] [web]
Learning Image Representations Tied to Ego-Motion. D. Jayaraman and K. Grauman. ICCV 2015. [pdf] [code,data] [slides]
Pairwise
Decomposition of Image Sequences for Active Multi-View
Recognition. E. Johns, S. Leutenegger, A.
Davison. CVPR 2016. [pdf]
Autonomously
Acquiring Instance-Based Object Models from
Experience. J. Oberlin and S. Tellex. ISRR
2015 [pdf]
Learning to Poke by Poking: Experiential Learning of Intuitive Physics. P. Agrawal, A. Nair, P. Abbeel, J. Malik, S. Levine. 2016 [pdf] [web]
Look-Ahead Before You Leap: End-to-End Active Recognition by Forecasting the Effect of Motion. D. Jayaraman and K. Grauman. ECCV 2016. [pdf]Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation. Y. Liu, A. Gupta, P. Abeel, S. Levine. 2017. [pdf] [video]
Deep Q-Learning for active recognition of GERMS: Baseline performance on a standardized dataset for active learning. Malmir et al. BMVC 2015. [pdf] [data]
Interactive Perception: Leveraging Action in Perception and Perception in Action. J. Bogh, K. Hausman, B. Sankaran, O. Brock, D. Kragic, S. Schaal, G. Sukhatme. IEEE Trans. on Robotics. 2016. [pdf]
Revisiting Active Perception. R. Bajcsy, Y. Aloimonos, J. Tsotsos. 2016. [pdf]
Learning
attentional policies for tracking and recognition in
video with deep networks. L. Bazzani, H.
Larochelle, V. Murino, J. Ting, N. de Freitas.
ICML 2011. [pdf]
BigBIRD Berkeley Instance Recognition Dataset and paper
CVPR 2017 Workshop on Visual Understanding Across Modalities
THOR challenge to navigate and find objects in a virtual environment
SUNCG dataset for indoor scenes
CVPR 2017 Workshop on Deep Learning for Robotic Vision
3D ShapeNets
Princeton ModelNet
iLab-20M dataset
GERMS Dataset for active object recognition
RGB-D Sensorimotor Object dataset
Experiments (with partner)
Proponent/opponent:
- Lakshay
- Paul
- Santhosh
- Shubham
- Arjun
Analyzing people in the scene. Re-identification, attributes, gaze following, crowds, faces, clothing fashion.

Image credit: Z. Cao et al.
« End-to-End Localization and Ranking for Relative Attributes. K. Singh and Y. J. Lee. ECCV 2016. [pdf] [code]
« Learning Visual Clothing Style with Heterogeneous Dyadic Co-occurrences. Veit*, Andreas; Kovacs*, Balazs; Bell, Sean; McAuley, Julian; Bala, Kavita; Belongie, Serge. ICCV 2015. [pdf] [code/data]
¤ Finding Tiny Faces. P. Hu, D. Ramanan. CVPR 2017. [pdf] [data/code]
¤ Learning from Synthetic Humans. G. Varol, J. Romero, X. Martin, N. Mahmood, M. Black, I. Laptev, C. Schmid. CVPR 2017. [pdf] [data] [code/videos]
¤ Synthesizing Normalized Faces from Facial Identity Features. F. Cole, D. Belanger, D. Krishnan, A. Sarna I. Mosseri, W. Freeman CVPR 2017. [pdf] [video]
Unsupervised Adaptive Re-identification in Open World Dynamic Camera Networks. Panda et al. CVPR 2017. [pdf]
Social Saliency Prediction. H. S. Park and J. Shi. CVPR 2015 [pdf]
Eye Tracking for Everyone. K. Krafka, A. Khosla, P. Kellnhofer, S. Bhandarkar, W. Matusik and A. Torralba. CVPR 2016. [pdf] [web/data]
Human Pose Estimation with Iterative Error Feedback. J. Carreira, P. Agrawal, K. Fragkiadaki, J. Malik. CVPR 2016. [pdf] [code]
Where are they looking? Khosla, Recasens, Vondrick, Torralba. NIPS 2015. [pdf] [demo] [web]
Detecting Events and Key Actors in Multi-Person Videos. V. Ramanathan, J. Huang, S. Abu-El-Haija, A. Gorban, K. Murphy, L. Fei-Fei. CVPR 2016. [pdf] [project/data]
Person Re-identification by Local Maximal Occurrence Representation and Metric Learning. S. Liao, Y. Hu, X. Zhu, S. Li. CVPR 2015. [pdf] [code/features]
Real-time human pose recognition in parts from single depth images. J. Shotton et al. CVPR 2011. [pdf] [video]
Hipster Wars: Discovering Elements of Fashion Styles. M. Kiapour, K. Yamaguchi, A. Berg, and T. Berg. ECCV 2014. [pdf] [game] [dataset]
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang. CVPR 2016. [pdf] [web]
Deep Domain Adaptation for Describing People Based on Fine-Grained Clothing Attributes. Q. Chen, J. Huang, R. Feris, L. Brown, J. Dong, S. Yan. CVPR 2015 [pdf]
Socially Aware Large-Scale Crowd Forecasting. A.
Alahi, V. Ramanathan, L. Fei-Fei. CVPR
2014. [pdf]
[data]
SURREAL dataset
ICCV 2017 Workshop on PeopleCap
MS-Celeb-1M Recognizing 1 Million Celebrities
CVPR 2017 Faces in the Wild Workshop Challenge
MPII Human Pose Dataset
UCI Proxemics Recognition Dataset
BodyLabs Mosh app
WiderFace Face detection benchmark
PRW Person re-identification in the wild dataset
MARS dataset for person re-identification
PRID 2011 dataset
iLIDS-VID dataset
Face detection code in OpenCV
Gallagher's Person Dataset
Face data from Buffy episode, from Oxford Visual Geometry Group
CALVIN upper-body detector code
UMass Labeled Faces in the Wild
FaceTracer database from Columbia
Database of human attributes
Stanford Group Discovery dataset
IMDB-WIKI 500k+ face images with age and gender labels, and names
Fashion Synthesis
Experiments (with partner)
Proponent/opponent:
- Chia-Chen
- Paul
- Xingyi
- Keivaun
- Wonjoon
- Chia-Wen
Discovering visual patterns within large-scale community photo collections. Correlating visual and non-visual properties. Street view data and Flickr photos. Demograhics, geography, ecology, brands, fashion.

Image credit: Arietta et al.
« City Forensics: Using Visual Elements to Predict Non-Visual City Attributes. Arietta, Efros, Ramammoorthy, Agrawala. Trans on Visualization and Graphics, 2014. [pdf] [web]
« Mapping the World's Photos. D. Crandall, L. Backstrom, D. Huttenlocher, J. Kleinberg. WWW 2009. [pdf] [web]
¤ Using Deep Learning and Google Street View to Estimate the Demographic Makeup of the US. T. Gebru, J. Krause, Y. Wang, D. Chen, J. Deng, E. Aiden, L. Fei-Fei. 2017. [pdf]
¤ Visualizing Brand Associations from Web Community Photos. G. Kim and E. Xing. ACM WSDM 2014. [pdf] [web]
¤ Observing the Natural World with Flickr. J. Wang, M. Korayem, D. Crandall. ICCV 2013 Workshops. [pdf]
What Makes Paris Look Like Paris? C. Doersch, S. Singh, A. Gupta, J. Sivic, A. Efros. SIGGRAPH 2012. [pdf] [web/code]
Learning the Latent "Look": Unsupervised Discovery of a Style-Coherent Embedding from Fashion Images. W-L. Hsiao and K. Grauman. ICCV 2017. [pdf] [project page/code]
A Century of Portraits: A Visual Historical Record of American High School Yearbooks. S. Ginosar, K. Rakelly, S. Sachs, B. Yin, and A. Efros. ICCV 2015 Extreme Imaging Workshop. [pdf] [web]
Clues from the Beaten Path: Location Estimation with Bursty Sequences of Tourist Photos. C.-Y. Chen and K. Grauman. CVPR 2011. [pdf] [project page] [data]
Tracking Natural Events through Social Media and Computer Vision. J. Wang, M. Korayem, S. Blanco, D. Crandall. ACM MM 2016. [pdf]
Style-Aware Mid-level Representation for Discovering Visual Connections in Space and Time. Y. J. Lee, A. Efros, M. Hebert. ICCV 2013. [pdf] [web/code]
Modeling and Recognition of Landmark Image Collections Using Iconic Scene Graphs. X. Li, C. Wu, C. Zach, S. Lazebnik, J. Frahm. IJCV 2011 [pdf] [web]
Experiments (with partner)
Proponent/opponent:
- Lakshay
- Wei-Jen
- Hsin-Ping
- Taylor
- Santiago
- Ginevra
Predicting or leveraging what gets noticed or remembered in images and video. Gaze, saliency, importance, memorability, summarization.

Image credit: N. Karessli et al.
« Gaze Embeddings for Zero-Shot Image Classification. N. Karessli, Z. Akata, B. Schiele, A. Bulling. CVPR 2017. [pdf]
« Video Summarization by Learning Submodular Mixtures of Objectives. M. Gygli, H. Grabner, L. Van Gool. CVPR 2015 [pdf] [code]
¤ Deep 360 Pilot: Learning a Deep Agent for Piloting Through 360° Sports Videos, Hou-Ning Hu, Yen-Chen Lin, Ming-Yu Liu, Hsien-Tzu Cheng, Yung-Ju Chang, Min Sun. CVPR 2017 [pdf] [code]
¤ End-to-end Learning of Action Detection from Frame Glimpses in Videos. S. Yeung, O. Russakovsky, G. Mori, L. Fei-Fei. CVPR 2016. [pdf] [code] [web]
Learning Visual Attention to Identify People with Autism Spectrum Disorder. M. Jiang and Q. Zhao. ICCV 2017. [pdf]
Making 360 Video Watchable in 2D: Learning Videography for Click Free Viewing. Y-C. Su and K. Grauman. CVPR 2017. [pdf] [videos] [slides]
The Secrets of Salient Object Segmentation. Y. Li, X. Hou, C. Koch, J. Rehg, A. Yuille. CVPR 2014 [pdf] [code]
Hierarchically Attentive RNN for Album Summarization and Storytelling. L. Yu, M. Bansal, T. Berg. EMNLP 2017. [pdf]
Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition S. Mathe, C. Sminchisescu. PAMI 2015 [pdf] [data]
Understanding and Predicting Image Memorability at a Large Scale. A. Khosla, S. Raju, A. Torralba, and A. Oliva. ICCV 2015. [pdf] [web] [code/data]
What is a Salient Object? A Dataset and Baseline Model for Salient Object Detection. A. Borji. IEEE TIP 2014 [pdf]
Saliency Revisited: Analysis of Mouse Movements versus Fixations. H. Tavakoli, F. Ahmed, A. Borji, J. Laaksonen. CVPR 2017. [pdf]
Learning video saliency from human gaze using candidate selection. D. Rudoy et al. CVPR 2013 [pdf] [web] [video] [code]
Video Summarization with Long Short-term Memory. K. Zhang, W-L. Chao, F. Sha, and K. Grauman. ECCV 2016 [pdf]
Predicting Important Objects for Egocentric Video Summarization. Y. J. Lee and K. Grauman. IJCV 2015. [pdf]
Pixel Objectness. S. Jain, B. Xiong, K. Grauman. 2017 [pdf]
Learning to Detect a Salient Object. T. Liu et al. CVPR 2007. [pdf] [results] [data] [code]
Learning Prototypical Event Structure from Photo Albums. A. Bosselut, J. Chen, D. Warren, H. Hajishirzi, Y. Choi. ACL 2016. [pdf] [data]
Storyline Representation of Egocentric Videos with an Application to Story-Based Search. B. Xiong, G. Kim, L. Sigal. ICCV 2015 [pdf]
Training Object Class Detectors from Eye Tracking Data. D. P. Papadopoulos, A. D. F. Clarke, F. Keller and V. Ferrari. ECCV 2014. [pdf] [data]
Salient Object Detection benchmark
Saliency datasets
The DIEM Project: visualizing dynamic images and eye movements
MIT eye tracking data
LaMem Demo
LaMem Dataset
MSRA salient object database
MED video summaries dataset
ETHZ video summaries dataset
VSUMM dataset for video summarization
UT Egocentric dataset / important regions
Salient Montages dataset
IBM Watson movie trailer generation
Experiments (with partner)
Proponent/opponent:
- Yajie
- Chia-Chen
- Darshan
- Thomas
- Taylor
- Santiago
Connecting language and vision. Captioning, referring expressions, question answering, word-image embeddings, attributes, storytelling

Image credit: J. Mao et al.
ICCV 2017. [pdf] [code/data] [demo]
« From Red Wine to Red Tomato: Composition with Context. I. Misra, A. Gupta, M. Hebert. CVPR 2017 [pdf]
« A Joint Speaker-Listener-Reinforcer Model for Referring Expressions. Licheng Yu, Hao Tan, Mohit Bansal, Tamara L. Berg. CVPR 2017 [pdf] [web]
¤ Learning deep structure-preserving
image-text embeddings. Wang, Liwei, Yin Li, and Svetlana
Lazebnik. CVPR 2016 [pdf] [code]
¤ Reasoning about Pragmatics with
Neural Listeners and Speakers. J. Andreas and D.
Klein. EMNLP 2016 [pdf]
[code]
¤ Visual Question
Answering. S. Antol, A. Agrawal, J. Lu, M.
Mitchell, D. Batra, C. Zitnick, D. Parikh. ICCV
2015 [pdf][data/code/demo]
Generation and Comprehension of Unambiguous Object Descriptions. J. Mao, J. Huang, A. Toshev, O. Camburu, A. Yuille, K. Murphy. CVPR 2016. [pdf] [data/web] [code]
DeViSE: A Deep Visual-Semantic Embedding Model. A. Frome, G. Corrado, J. Shlens, S. Bengio, J. Dean, M. Ranzato, T. Mikolov. NIPS 2013 [pdf]
Visual Storytelling. T-H. Huang et
al. NAACL 2016 [pdf]
[data]
GuessWhat?! Visual Object Discovery
Through Multi-Modal Dialogue. H. de Vries et
al. CVPR 2017 [pdf]
Visual Mad Libs: Fill in the Blank
Description Generation and Question Answering. L.
Yu, E. Park, A. Berg, T. Berg. ICCV 2015 [pdf]
[video]
[data]
Deep Compositional Captioning: Describing
Novel Object Categories without Paired Training
Data. L. Hendricks, S. Venugopalan, M. Rohrbach,
R. Mooney, K. Saenko, T. Darrell. CVPR 2016.
[pdf]
Stacked attention networks for image
question answering. Z. Yang, X. He, J. Gao, L. Deng, A.
Smola. CVPR 2016. [pdf] [code]
Neural Module Networks. J. Andreas, M. Rohrbach, T. Darrell, D. Klein. CVPR 2016. [pdf] [code]
Where to Look: Focus Regions for Visual
Question Answering. K. Shih, S. Singh, D.
Hoiem. CVPR 2016. [pdf] [web/code]
MovieQA: Understanding Stories in Movies
through Question-Answering. M. Tapaswi, Y. Zhu, R.
Stiefelhagen, A. Torralba, R. Urtasun, S. Fidler. CVPR
2016. [pdf]
[web]
Sequence to Sequence - Video to
Text. S. Venugopalan et al. ICCV 2015
[pdf]
[web]
[code]
Ask Your Neurons: A Neural-Based Approach to Answering
Questions About Images. Malinowski, Rohrbach,
Fritz. ICCV 2015. [pdf]
[video]
[code/data]
CVPR 2016 VQA Challenge Workshop
COCO Captioning Challenge dataset
VideoSET
summary evaluation data
AbstractScenes
dataset
VizWiz dataset for QA
with blind users
Experiments (with partner):
Proponent/opponent:
- Rolando
- Wei-Jen
- Yu-Chuan
- Angela
- Keivaun