slides
Paper reviews for 2 papers due Monday Aug 29.
Invariant local features, local feature matching, instance recognition, visual vocabularies and bag-of-words, large-scale mining

image credit: Andrea Vedaldi and Andrew Zisserman
« Video Google: A Text Retrieval Approach to Object Matching in Videos, Sivic and Zisserman, ICCV 2003. [pdf] [demo]
« Local Invariant Feature Detectors: A Survey,
Tuytelaars and Mikolajczyk. Foundations and Trends
in Computer Graphics and Vision, 2008. [pdf]
[Oxford
code] [Selected
pages -- read pp. 178-188, 216-220, 254-255]
For more background on feature extraction: Szeliski book: Sec 3.2 Linear filtering, 4.1 Points and patches, 4.2 Edges
SIFT meets CNN: A Decade Survey of Instance Retrieval. L. Zheng, Y. Yang, Q. Tian. [pdf]Andrea Vedaldi's VLFeat code, including SIFT, MSER, hierarchical k-means.
INRIA LEAR team's software, including interest points, shape features
FLANN - Fast Library for Approximate Nearest Neighbors. Marius Muja et al.
Code for downloading Flickr images, by James Hays
UW Community Photo Collections homepage
INRIA Holiday images dataset
NUS-WIDE tagged image dataset of 269K images
MIRFlickr dataset
Dataset index
slides
Image descriptors, classifiers, support vector machines, nearest neighbors, convolutional neural networks, large-scale image collections

Image credit: ImageNet
« ImageNet Classification with Deep Convolutional Neural Networks. A. Krizhevsky, I. Sutskever, and G. Hinton. NIPS 2012 [pdf]
« Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories, Lazebnik, Schmid, and Ponce, CVPR 2006. [pdf] [15 scenes dataset] [libpmk] [Matlab]
80 Million tiny images: a large dataset for non-parametric object and scene recognition. A. Torralba, R. Fergus, and W. Freeman. PAMI 2008. [pdf]
Deep Neural Decision Forests. Peter Kontschieder, Madalina Fiterau, Antonio Criminisi, Samuel Rota Bulo. ICCV 2015. [pdf]
Deep Residual Learning for Image Recognition Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun, CVPR 2016. [pdf]
Very deep convolutional networks for large-scale image recognition. K. Simonyan and A. Zisserman, ICLR 2015 [pdf]
ConvNets
for Visual Recognition course, Andrej Karpathy,
Stanford
Machine
learning with neural nets lecture, Geoffrey Hinton
Deep
learning course, Bhiksha Raj, CMU
Deep learning in
neural networks: an overview, Juergen Schmidhuber.
Benchmarking State-of-the-Art Deep
Learning Software Tools. S. Shi, Q. Wang, P. Xu,
X. Chu. 2016. [pdf]
Practical tips:
CNN resources
VGG Net
Scenes - PlaceNet
VLFeat code
LIBPMK feature extraction code, includes dense sampling
LIBSVM library for support vector machines
PASCAL VOC Visual Object Classes Challenge
Deep learning portal, with Theano tutorials
Colah's blog
Deep learning blog
iPython notebook for Caffe
Tips for Caffe OS X El Capitan
slides
tutorial slides:
deep learning primer
(longer version)
Caffe primer
Caffe primer codes github repo
GDC 5.302 (NOT usual classroom)
Segmentation into regions, contours, grouping, video segmentation, category-independent object proposals, object detection with proposals or windows, semantic segmentation

Image credit: Fanyi Xiao and Yong Jae Lee
« Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. R. Girshick, J. Donahue, T. Darrell, J. Malik. CVPR 2013 [pdf] [supp] (see also fast R-CNN, and faster R-CNN)
¤ Constrained Parametric Min-Cuts for Automatic Object Segmentation. J. Carreira and C. Sminchisescu. CVPR 2010. [pdf] [code]
¤ Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs Chen, Papandreou, Kokkinos, Murphy, Yuille. ICLR 2015. [pdf] [code/data]
Efficient Hierarchical Graph-Based Video Segmentation. M. Grundmann, V. Kwatra, M. Han, and I. Essa. CVPR 2010. [pdf] [code,demo]
Supervoxel-Consistent Foreground Propagation in Video. S. Jain and K. Grauman. ECCV 2014. [pdf] [project page] [data]
Selective Search for Object Recognition. J. Uijilings, K. van de Sande, T. Gevers, A. Smeulders. IJCV 2013. [pdf] [project,code]
Streaming hierarchical video segmentation. C. Xu, C. Xiong, J. Corso. ECCV 2012. [pdf] [code]
A Discriminatively Trained, Multiscale, Deformable Part Model, by P. Felzenszwalb, D. McAllester and D. Ramanan. CVPR 2008. [pdf] [code]
Microsoft COCO: Common Objects in Context. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, C. Lawrence Zitnick, ECCV 2014. [pdf]
Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, T. Darrell. CVPR 2015. [pdf] [models]
Hypercolumns for Object Segmentation and Fine-Grained Localization. B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik. CVPR 2015 [pdf] [code]
Simultaneous Detection and Segmentation. B. Hariharan, P. Arbelaez, R. Girshick, J. Malik. ECCV 2014. [pdf] [code]
Learning to Segment Moving Objects in Videos. K. Fragkiadaki, P. Arbelaez, P. Felsen, J. Malik. CVPR 2015 [pdf]
Fast SLIC superpixels
Greg Mori's superpixel code
Berkeley Segmentation Dataset and code
Pedro Felzenszwalb's graph-based segmentation code
Mean-shift: a Robust Approach Towards Feature Space Analysis [pdf] [code, Matlab interface by Shai Bagon]
David Blei's Topic modeling code
Berkeley 3D object dataset (kinect)
Labelme Database
Scene Understanding Symposium
PASCAL VOC Visual Object Classes Challenge
Hoggles
Dataset index
slides
Expt-Harshal
Paper-Brady
Paper-Josh
Discuss: Zhenpei, Tushar, Nayan
Unsupervised feature learning from "free" side information (tracks in video, spatial layout in images, multi-modal sensed data, ego-motion).

Image credit: Jing Wang et al.
« Walk and Learn: Facial Attribute Representation Learning from Egocentric Video and Contextual Data. J. Wang, Y. Cheng, and R. Feris. CVPR 2016. [pdf]
¤ Ambient Sound Provides Supervision for Visual Learning. A. Owens, J. Wu, J. McDermottt, W. Freeman, A. Torralba. ECCV 2016. [pdf]
¤ Learning Representations for Automatic Colorization. G. Larsson, M. Maire, and G. Shakhnarovich. ECCV 2016. [pdf] [web] [code] [demo]
Visually Indicated Sounds. A. Owens, P. Isola, J. McDermott, A. Torralba, E. Adelson, W. Freeman. CVPR 2016. [pdf] [web/data]
Learning Image Representations Equivariant to Ego-motion. D. Jayaraman and K. Grauman. ICCV 2015. [pdf] [web] [slides] [data] [models]
Unsupervised learning of visual representations using videos. X. Wang and A. Gupta. ICCV 2015. [pdf] [code] [web]
Slow and Steady Feature Analysis: Higher Order Temporal Coherence in Video. D. Jayaraman and K. Grauman. CVPR 2016. [pdf]
Object-Centric Representation Learning from Unlabeled Videos. R. Gao, D. Jayaraman, and K. Grauman. ACCV 2016. [pdf]
Unsupervised learning of visual representations by solving jigsaw puzzles. M. Noroozi and P. Favaro. 2016 [pdf]
Learning to See by Moving. P. Agrawal, J. Carreira, J. Malik. ICCV 2015. [pdf]
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification. I. Misra, C. Zitnick, M. Hebert. ECCV 2016. [pdf]
Expt-Yiming
Expt-Tushar
Paper-An
Discuss: Harshal, Wei-Lin, Vivek, Ambika
Visual properties, adjectives, relative comparisons; learning from natural language descriptions, intermediate shared representations, applications in fashion and street-view prediction tasks
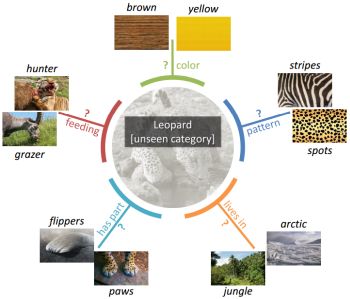
Image credit: Ziad Al-Halah et al.
« Recovering the Missing Link: Predicting Class-Attribute Associations for Unsupervised Zero-Shot Learning. Z. Al-Halah, M. Tapaswi, and R. Stiefelhagen. CVPR 2016 [pdf] [features]
« Relative Attributes. D. Parikh and K. Grauman. ICCV 2011. [pdf] [code/data]
¤ City Forensics: Using Visual Elements to Predict Non-Visual City Attributes. Arietta, Efros, Ramammoorthy, Agrawala. Trans on Visualization and Graphics, 2014. [pdf] [web]
¤ Street-to-Shop: Cross-Scenario Clothing Retrieval via Parts Alignment and Auxiliary Set. S. Liu, Z. Song, G. Liu, C. Xu, H. Lu, and S. Yan. CVPR 2012. [pdf]
Hipster Wars: Discovering Elements of Fashion Styles. M. Kiapour, K. Yamaguchi, A. Berg, and T. Berg. ECCV 2014. [pdf] [game] [dataset]
Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer, C. Lampert, H. Nickisch, and S. Harmeling, CVPR 2009 [pdf] [web] [data]
End-to-End Localization and Ranking for Relative Attributes. K. Singh and Y. J. Lee. ECCV 2016. [pdf]
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. Z. Liu, P. Luo, S. Qiu, X. Wang, and X. Tang. CVPR 2016. [pdf] [web]
Discovering the spatial extent of relative attributes. F. Xiao and Y. J. Lee. ICCV 2015. [pdf] [code]
Multi-Cue Zero-Shot Learning With Strong Supervision, Zeynep Akata, Mateusz Malinowski, Mario Fritz, Bernt Schiele. CVPR 2016. [pdf]
Less is More: Zero-Shot Learning from Online Textual Documents with Noise Suppression. R. Qiao, L. Liu, C. Shen, and A. van den Hengel. CVPR 2016. [pdf]
Fine-Grained Visual Comparisons with Local Learning. A. Yu and K. Grauman. CVPR 2014. [pdf] [supp] [poster] [data] [project page]
Photo Aesthetics Ranking Network with Attributes and Content Adaptation. S. Kong, X. Shen, Z. Lin, R. Mech, and C. Fowlkes. ECCV 2016. [pdf]
Decorrelating Semantic Visual Attributes by Resisting the Urge to Share. D. Jayaraman, F. Sha, and K. Grauman. CVPR 2014. [pdf] [supp] [project page] [slides] [poster]
WhittleSearch: Interactive Image Search with Relative Attribute Feedback. A. Kovashka, D. Parikh, and K. Grauman. International Journal on Computer Vision (IJCV), Volume 115, Issue 2, pp 185-210, November 2015. [link] [arxiv] [demo] [project page]
Deep Domain Adaptation for Describing People Based on Fine-Grained Clothing Attributes. Q. Chen, J. Huang, R. Feris, L. Brown, J. Dong, S. Yan. CVPR 2015 [pdf]
aYahoo and aPascal attributes datasets
Attribute discovery dataset of shopping categories
Public Figures Face database with attributes
Relative attributes data
WhittleSearch relative attributes data
SUN Scenes attribute dataset
Cross-category object recognition (CORE) dataset
Leeds Butterfly Dataset
FaceTracer database from Columbia
Caltech-UCSD Birds dataset
Database of human attributes
More attribute datasets
2014 Workshop on Parts & Attributes
UT Zappos 50K dataset
Dataset index
UT Austin MLSS Attributes lecture
CVPR 2013 Attributes tutorial
Expt-Mit
Expt-Wei-Lin
Discuss: Dongguang, An, Josh, Dan
Detecting activities, actions, and events in images or video. Recognition challenges, relating actions to scenes, video descriptors, interactions with objects.

Image credit: H. Wang and C. Schmid
« The
Open World of Micro-Videos. P. Nguyen, G. Rogez,
C. Fowlkes, and D. Ramanan. 2016 [pdf]
« Situation
Recognition: Visual Semantic Role Labeling for Image
Understanding. M. Yatskar, L. Zettlemoyer, and
A. Farhadi. [pdf]
[demo/data/code]
« Action Recognition with Improved
Trajectories. H. Wang and C.
Schmid. ICCV 2013. [pdf]
[web/code]
¤ SceneGrok:
Inferring Action Maps in 3D Environments. M.
Savva, A. Chang, P. Hanrahan, M. Fisher, and M.
Niebner. [pdf]
[web/data]
¤ Anticipating
Visual Representations from Unlabeled Video. C.
Vondrick, H. Pirsiavash, and A. Torralba. CVPR
2016. [pdf]
End-to-end learning of action detection from frame
glimpses in videos. Yeung, S.,
Russakovsky, O., Mori, G., Fei-Fei, L. CVPR
2016. [pdf]
[web]
C3D:
Generic features for video analysis. D. Tran, L.
Bourdev, R. Fergus, L. Torresani, and M. Paluri. [pdf]
Actions~Transformations. X. Wang, A. Farhadi, and A. Gupta. CVPR 2016. [pdf] [data]
People Watching: Human Actions as a Cue for Single View Geometry. Fouhey, Delaitre, Gupta, Efros, Laptev, Sivic. ECCV 2012 [pdf] [journal] [web] [slides] [video]
Temporal
Action Localization in Untrimmed Videos via Multi-stage
CNNs. Z. Shou, D. Wang, and S-F. Chang. CVPR
2016. [pdf]
[code]
Regularizing Long Short Term Memory with 3D Human-Skeleton Sequences for Action Recognition. B. Mahasseni and S. Todorovic. CVPR 2016. [pdf]
Activity
Forecasting. K. Kitani, B. Ziebart, J. Bagnell and
M. Hebert. ECCV 2012. [pdf]
[data/code]
Fast Temporal Activity Proposals for Efficient Detection of Human Actions in Untrimmed Videos. F. Heilbron, J. Niebles, and B. Ghanem. CVPR 2016. [pdf] [web] [code]
Efficient
Activity Detection in Untrimmed Video with Max-Subgraph
Search. C-Y. Chen and K.
Grauman. IEEE Trans. on Pattern Analysis and
Machine Intelligence (PAMI), April 2016. [pdf] [web]
[code]
Hollywood
in Homes: Crowdsourcing Data Collection for Activity
Understanding. G. Sigurdsson, G. Varol, X. Wang,
A. Farhadi, I. Laptev, and A. Gupta. ECCV
2016. [pdf] [web/data]
What do
15,000 object categories tell us about classifying and
localizing actions? Jain, M., van Gemert, J.C.,
Snoek, C.G.M. CVPR 2015. [pdf]
Two-stream
convolutional networks for action recognition in
videos. Simonyan, K., Zisserman, A. NIPS
2014. [pdf]
Dataset index
Chao-Yeh Chen's compiled list of activity datasets
UCF-101 dataset
Olympic sports dataset
Charades dataset
Activitynet
THUMOS action detection dataset
Paper-Dan
Expt-Brady
Expt-Nayan
Discuss: Vivek, Ambika, Hangchen
hw2 leader board
Egocentric wearable cameras. Recognizing actions and manipulated objects, predicting gaze, discovering patterns and anomalies, temporal segmentation, estimating physical properties

Image credit: Krishna Kumar Singh et al.
« KrishnaCam: Using a Longitudinal, Single-Person, Egocentric Dataset for Scene Understanding Tasks. K. Singh, K. Fatahalian, and A. Efros. WACV 2016 [pdf] [web/data]
« You-Do, I-Learn: Discovering Task Relevant Objects and their Modes of Interaction from Multi-User Egocentric Video. D Damen, T. Leelasawassuk, O Haines, A Calway, W Mayol-Cuevas. BMVC 2014. [pdf] [data]
¤ Temporal Segmentation of Egocentric Videos. Y. Poleg, C. Arora, and S. Peleg. CVPR 2014. [pdf] [code/data]
¤ Force from Motion: Decoding Physical Sensation from a First Person Video. H.S. Park, J-J. Hwang and J. Shi. CVPR 2016. [pdf] [web/data]
An Egocentric Look at Video Photographer Identity, Y. Hoshen and S. Peleg. CVPR 2016. [pdf]
Visual Motif Discovery via First-Person Vision. R. Yonetani, K. Kitani, and Y. Sato. ECCV 2016. [pdf]
Predicting Important Objects for Egocentric Video Summarization. Y. J. Lee and K. Grauman. IJCV 2015 [pdf] [web]
Learning Action Maps of Large Environments via First-Person Vision. N. Rhinehart, K. Kitani. CVPR 2016. [pdf] [slides]
Fast Unsupervised Ego-Action Learning for First-person Sports Videos. Kris M. Kitani, Takahiro Okabe, Yoichi Sato, and Akihiro Sugimoto. CVPR 2011 [pdf]
Egocentric Future Localization. H. S. Park, J-J. Hwang, Y. Niu, and J. Shi. CVPR 2016. [pdf] [web]
Figure-Ground Segmentation Improves Handled Object Recognition in Egocentric Video. X. Ren and C. Gu, CVPR 2010. [pdf] [video] [dataset]
Compact CNN for Indexing Egocentric Videos. Y. Poleg, A. Ephrat, S. Peleg, C. Arora. WACV 2015 [pdf]
Delving into Egocentric Actions, Y. Li, Z. Ye, and J. Rehg. CVPR 2015. [pdf]
Detecting Engagement in Egocentric Video. Y-C. Su and K. Grauman. ECCV 2016 [pdf]
Understanding Everyday Hands in Action from RGB-D Images. G. Rogez, J. Supancic, D. Ramanan. ICCV 2015. [pdf]
Recognizing Activities of Daily Living with a Wrist-mounted Camera. K. Ohnishi, A. Kanehira, A. Kanezaki, and T. Harada. CVPR 2016. [pdf] [poster]
PlaceAvoider: Steering First-Person Cameras away from Sensitive Spaces. R. Templeman, M. Korayem, D. Crandall, and A. Kapadia. NDSS 2014. [pdf]
Enhancing Lifelogging Privacy by Detecting Screens. M. Korayem, R. Templeman, D. Chen, D. Crandall, and A. Kapadia. CHI 2016. [pdf] [web]
EgoSampling: Wide View Hyperlapse from Single and Multiple Egocentric Videos. T. Halperin, Y. Poleg, C. Arora, and S. Peleg. 2016 [pdf]
Story-driven Summarization for Egocentric Video. Z. Lu and K. Grauman. CVPR 2013 [pdf]
Modeling actions through state changes. A Fathi and J Rehg. CVPR 2013. [pdf]
Bristol Egocentric Object Interactions Dataset
UT Egocentric Dataset
Intel Egocentric Vison dataset
GTEA
GTEA Gaze
Ego-surfing dataset
CMU Multi-Modal Activity Database (kitchen)
Detecting Activities of Daily Living (ADL) dataset
Walk to Work dataset for novelty detection
JPL First-Person Interaction dataset
Multimodal Egocentric Activity Dataset - lifelogging
EgoGroup group activities dataset
UI EgoHands dataset
CMU Zoombie dataset walking with hands
GUN 71 grasps dataset
Paper-Vivek
Expt-Wenguang
Expt-Ambika
Discuss: Dongguang, Brady, Mit, Dan
Learning how to move for recognition, manipulation. 3D objects and the next best view. Active selection of next observations for cost-sensitive recognition.
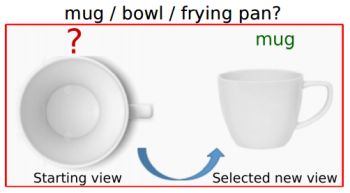
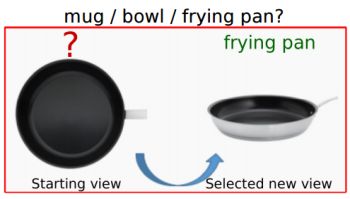
Image credit: Dinesh Jayaraman
« Pairwise
Decomposition of Image Sequences for Active Multi-View
Recognition. E. Johns, S. Leutenegger, A.
Davison. CVPR 2016. [pdf]
¤ Timely object recognition. Karayev, S., Baumgartner, T., Fritz, M., Darrell, T. NIPS 2012 [pdf] [code] [slides]
3D ShapeNets: A Deep Representation for Volumetric Shape Modeling. Wu et al. CVPR 2015. [pdf] [code/data] [slide]
Deep Q-learning for active recognition of GERMS: Baseline performance on a standardized dataset for active learning. Malmir et al. BMVC 2015. [pdf] [data]
Interactive Perception: Leveraging Action in Perception and Perception in Action. J. Bogh, K. Hausman, B. Sankaran, O. Brock, D. Kragic, S. Schaal, G. Sukhatme. IEEE Trans. on Robotics. 2016. [pdf]
Revisiting Active Perception. R. Bajcsy, Y. Aloimonos, J. Tsotsos. 2016. [pdf]
Learning to Poke by Poking: Experiential Learning of Intuitive Physics. P. Agrawal, A. Nair, P. Abbeel, J. Malik, S. Levine. 2016 [pdf] [web]
Learning
attentional policies for tracking and recognition in
video with deep networks. L. Bazzani, H.
Larochelle, V. Murino, J. Ting, N. de Freitas.
ICML 2011. [pdf]
Optimal
scanning for faster object detection. Butko, N.,
Movellan, J. CVPR 2009 [pdf]
An active
search strategy for efficient object detection.
Garcia, A.G., Vezhnevets, A., Ferrari, V. CVPR
2015. [pdf]
Leaving
Some Stones Unturned: Dynamic Feature Prioritization for
Activity Detection in Streaming Video. Y-C. Su and
K. Grauman. ECCV 2016. [pdf]
3D ShapeNets
Princeton ModelNet
iLab-20M dataset
Paper-Nayan
Expt-Dongguang
Discuss: Jimmy, Zhenpei, Wenguang
Predicting what gets noticed or remembered in images and video. Gaze, saliency, importance, memorability, mentioning biases.

Image credit: Y. Li et al.
« The Secrets of Salient Object Segmentation. Y. Li, X. Hou, C. Koch, J. Rehg, A. Yuille. CVPR 2014 [pdf] [code]
¤ Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition S. Mathe, C. Sminchisescu. PAMI 2015 [pdf] [data]
¤ Understanding and Predicting Image Memorability at a Large Scale. A. Khosla, S. Raju, A. Torralba, and A. Oliva. ICCV 2015. [pdf] [web] [code/data]
Learning video saliency from human gaze using candidate selection. D. Rudoy et al. CVPR 2013 [pdf] [web] [video] [code]
Learning to Detect a Salient Object. T. Liu et al. CVPR 2007. [pdf] [results] [data] [code]
Salient
Object Detection: A Benchmark. A. Borji, D.
Sihite, L. Itti. ECCV 2012. [pdf]
Eye
Tracking for Everyone. K. Krafka, A. Khosla, P.
Kellnhofer, S. Bhandarkar, W. Matusik and A.
Torralba. CVPR 2016. [pdf]
[web/data]
Understanding and Predicting Importance in Images. A. Berg et al. CVPR 2012 [pdf]
Salient Object Detection benchmark
Saliency datasets
The DIEM Project: visualizing dynamic images and eye movements
MIT eye tracking data
LaMem Demo
LaMem Dataset
MSRA salient object database
MED video summaries dataset
ETHZ video summaries dataset
VSUMM dataset for video summarization
UT Egocentric dataset / important regions
Salient Montages dataset
Paper-Ambika
Expt-Jimmy
Expt-An
Discuss: Hangchen, Kate, Tushar, Nayan
Analyzing people in the scene. Re-identification, attributes, gaze following, crowds.

« What's in a Name: First Names as Facial Attributes. H. Chen, A. Gallagher, and B. Girod. CVPR 2013. [pdf] [web/code] [demo]
« Person Re-identification by Local Maximal Occurrence Representation and Metric Learning. S. Liao, Y. Hu, X. Zhu, S. Li. CVPR 2015. [pdf] [code/features]¤ Where are they looking? Khosla, Recasens, Vondrick, Torralba. NIPS 2015. [pdf] [demo] [web]
¤ Socially Aware Large-Scale Crowd Forecasting. A. Alahi, V. Ramanathan, L. Fei-Fei. CVPR 2014. [pdf] [data]
Social
Saliency Prediction. H. S. Park and J. Shi.
CVPR 2015 [pdf]
Social
LSTM: Human Trajectory Prediction in Crowded
Spaces. A. Alahi, K. Goel, V. Ramanathan, A.
Robicquet, L. Fei-Fei, S. Savarese. CVPR
2016. [pdf]
Learning
Social Etiquette: Human Trajectory Prediction. A.
Robicquet, A. Sadeghian, A. Alahi, S. Savarese.
ECCV 2016.
Detecting
Events and Key Actors in Multi-Person Videos. V.
Ramanathan, J. Huang, S. Abu-El-Haija, A. Gorban, K.
Murphy, and L. Fei-Fei. CVPR 2016. [pdf]
Person
Re-identification in the Wild. L. Zheng, H. Zhang,
S. SUn, M. Chandraker, Q. Tian. 2016. [pdf]
Top-Push
Video-based Person Re-identification. J. You, A.
Wu, X. Li, W-S. Zheng. CVPR 2016. [pdf]
Detecting People Looking at Each Other in Videos. M. Marin-Jimenez, A. Zisserman, M. Eichner, V. Ferrari. IJCV 2014 [pdf]
MARS dataset for person re-identification
PRID 2011 dataset
iLIDS-VID dataset
Face detection code in OpenCV
Gallagher's Person Dataset
Face data from Buffy episode, from Oxford Visual Geometry Group
CALVIN upper-body detector code
UMass Labeled Faces in the Wild
FaceTracer database from Columbia
Database of human attributes
Stanford Group Discovery dataset
IMDB-WIKI 500k+ face images with age and gender labels, and names
Paper-Wenguang
Expt-Dan
Expt-Zhenpei
Discuss: Yiming, An, Mit, Wei-Lin
Hand-drawn sketches and visual recognition. Retrieving natural images matching a sketch query, forensics applications, interactive drawing tools, fine-grained retrieval.

Image credit: P. Sangkloy et al.
« The
Sketchy Database: Learning to Retrieve Badly Drawn
Bunnies. P. Sangkloy, N. Burnell, C. Ham, and J.
Hays. SIGGRAPH 2016. [pdf]
[web] [code/model]
[database]
« ForgetMeNot: Memory-Aware Forensic Facial Sketch
Matching. S. Ouyang, T. Hospedales, Y-Z. Song, X.
Li. CVPR 2016. [pdf]
¤
ShadowDraw: Real-Time User Guidance for Freehand
Drawing. Y. J. Lee, C. L. Zitnick, M. Cohen.
SIGGRAPH 2011. [pdf]
[web/video/data]
¤ Sketch Me That Shoe. Q. Yu, F. Liu, Y-Z. Song, T. Xiang, T. Hospedales, C. Loy. CVPR 2016. [pdf] [code/data/model] [demo]
Learning to Simplify: Fully Convolutional Networks for
Rough Sketch Cleanup. SIGGRAPH 2016. [pdf]
[web/model]
Sketch-a-Net that Beats Humans. Q. Yu, Y. Yang, Y-Z. Song, T. Xiang, T. Hospedales. BMVC 2015. [pdf]
Scalable Sketch-based Image Retrieval Using Color Gradient Features. T. Bui and J. Collomosse. ICCV 2015. [pdf] [demo]
How Do Humans Sketch Objects? M. Eitz, J. Hays, M. Alexa. SIGGRAPH 2012. [pdf] [web/data]
Fine-Grained
Sketch-Based Image Retrieval by Matching Deformable Part
Modela. Y. Li, T. Hospedales, Y-Z. Song, S.
Gong. BMVC 2014. [pdf]
Sketch2Photo:
Internet Image Montage. T. Chen, M-M. Cheng, P.
Tan, A. Shamir, S-M. Hu. SIGGRAPH Asia 2009.
[pdf]
[web]
Convolutional Sketch Inversion. Y. Gucluturk, U. Guclu, R. van Lier, M. van Gerven. 2016 [pdf]
Face sketch photo dataset
Quickdraw
Paper-Wei-Lin
Expt-Hangchen
Expt-Josh
Discuss: Yiming, Kate, Brady
Connecting language and vision. Captioning, referring expressions, question answering, word-image embeddings, storytelling

Image credit: J. Mao et al.
« Generation and Comprehension of Unambiguous Object Descriptions. J. Mao, J. Huang, A. Toshev, O. Camburu, A. Yuille, K. Murphy. CVPR 2016. [pdf] [data/web] [code]
¤ DeViSE: A Deep Visual-Semantic
Embedding Model. A. Frome, G. Corrado, J. Shlens,
S. Bengio, J. Dean, M. Ranzato, T. Mikolov. NIPS
2013 [pdf]
¤ Visual Storytelling. T-H. Huang et al.
NAACL 2016 [pdf]
[data]
Deep Compositional Captioning: Describing
Novel Object Categories without Paired Training
Data. L. Hendricks, S. Venugopalan, M. Rohrbach,
R. Mooney, K. Saenko, T. Darrell. CVPR 2016.
[pdf]
Stacked attention networks for image
question answering. Z. Yang, X. He, J. Gao, L. Deng, A.
Smola. CVPR 2016. [pdf] [code]
Neural Module Networks. J. Andreas, M. Rohrbach, T. Darrell, D. Klein. CVPR 2016. [pdf] [code]
Where to Look: Focus Regions for Visual
Question Answering. K. Shih, S. Singh, D.
Hoiem. CVPR 2016. [pdf] [web/code]
MovieQA: Understanding Stories in Movies
through Question-Answering. M. Tapaswi, Y. Zhu, R.
Stiefelhagen, A. Torralba, R. Urtasun, S. Fidler. CVPR
2016. [pdf]
[web]
Sequence to Sequence - Video to
Text. S. Venugopalan et al. ICCV 2015
[pdf]
[web]
[code]
Ask Your Neurons: A Neural-Based Approach to Answering
Questions About Images. Malinowski, Rohrbach,
Fritz. ICCV 2015. [pdf]
[video]
[code/data]
Referitgame: Referring to objects in photographs of
natural scenes. S. Kazemzadeh, V. Ordonez, M.
Matten, and T. L. Berg. EMNLP 2014 [pdf]
CVPR 2016 VQA Challenge Workshop
COCO Captioning Challenge dataset
VideoSET
summary evaluation data
ReferIt dataset
Paper-Tushar
Expt-Vivek
Discuss: Jimmy, Harshal, Wenguang, Josh