Invariant local features, local feature matching, instance recognition, visual vocabularies and bag-of-words, large-scale mining

image credit: Andrea Vedaldi and Andrew Zisserman
-
*Object Recognition from Local Scale-Invariant Features, Lowe, ICCV 1999. [pdf] [code] [other implementations of SIFT] [IJCV]
-
*Local Invariant Feature Detectors: A Survey, Tuytelaars and Mikolajczyk. Foundations and Trends in Computer Graphics and Vision, 2008. [pdf] [Oxford code] [Selected pages -- read pp. 178-188, 216-220, 254-255]
-
*Video Google: A Text Retrieval Approach to Object Matching in Videos, Sivic and Zisserman, ICCV 2003. [pdf] [demo]
-
For more background on feature extraction: Szeliski book: Sec 3.2 Linear filtering, 4.1 Points and patches, 4.2 Edges
- Oxford group interest point software
- Andrea Vedaldi's VLFeat code, including SIFT, MSER, hierarchical k-means.
- INRIA LEAR team's software, including interest points, shape features
- FLANN - Fast Library for Approximate Nearest Neighbors. Marius Muja et al.
- Google Goggles
- Kooaba
- Code for downloading Flickr images, by James Hays
- UW Community Photo Collections homepage
- INRIA Holiday images dataset
- NUS-WIDE tagged image dataset of 269K images
- MIRFlickr dataset
outline
Image descriptors, classifiers, support vector machines, nearest neighbors, convolutional neural networks, large-scale image collections

Image credit: ImageNet
- *ImageNet Large Scale Visual
Recognition Challenge. Russakovsky et al. IJCV
2015. [pdf]
- *ImageNet Classification with Deep Convolutional Neural Networks. A. Krizhevsky, I. Sutskever, and G. Hinton. NIPS 2012 [pdf]
- *Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories, Lazebnik, Schmid, and Ponce, CVPR 2006. [pdf] [15 scenes dataset] [libpmk] [Matlab]
- *80 Million tiny images: a large
dataset for non-parametric object and scene
recognition. A. Torralba, R. Fergus, and W.
Freeman. PAMI 2008. [pdf]
- CNN resources
linked from Stanford CS231n course page
- CNN/NN open source implementations
- ConvNets for Visual Recognition course, Andrej Karpathy, Stanford
- Machine learning with neural nets lecture, Geoffrey Hinton
- Deep learning
course, Bhiksha Raj, CMU
- VGG Net
- Deep learning
in neural networks: an overview, Juergen
Schmidhuber.
- Scenes - PlaceNet
- VLFeat code
- LIBPMK feature extraction code, includes dense sampling
- LIBSVM library for support vector machines
- PASCAL VOC Visual Object Classes Challenge
- Deep
learning portal, with Theano tutorials
- Practical tips: Ilya Sutskever blog post
- Practical tips: Stanford course notes
- Practical tips: Bengio paper
- Colah's blog
- Deep learning blog
- iPython notebook for Caffe
- Tips
for Caffe OS X El Capitan
Intro to categorization and case studies of discriminative models
slides 2 handout
slides 2 with links
Guest lecture on CNNs, Dinesh Jayaraman
Tutorial slides
Tutorial code
Segmentation into regions, contours, grouping, video segmentation, category-independent object proposals, 3d structure

Image credit: Pablo Arbelaez et al.
-
*Constrained Parametric Min-Cuts for Automatic Object Segmentation. J. Carreira and C. Sminchisescu. CVPR 2010. [pdf] [code]
- *Selective Search for Object Recognition. J. Uijilings, K. van de Sande, T. Gevers, A. Smeulders. IJCV 2013. [pdf] [project,code]
- *Discriminatively trained dense surface normal estimation. L. Ladicky, B. Zeisl, M. Pollefeys. ECCV 2014. [pdf]
- Fast
SLIC superpixels
- Greg Mori's superpixel code
- Berkeley Segmentation Dataset and code
- Pedro Felzenszwalb's graph-based segmentation code
- Mean-shift: a Robust Approach Towards Feature Space Analysis [pdf] [code, Matlab interface by Shai Bagon]
- David Blei's Topic modeling code
- Berkeley 3D object dataset (kinect)
Paper-Chun-Chen Kuo
Paper-Andrew Sharp
Expt-Kim Houck
Expt-Chad Voegele
Localizing objects within an image, efficient search, part-based models, semantic segmentation, voting, context, objects in scenes

Image credit: Felzenszwalb et al.
- *Rich feature hierarchies for accurate
object detection and semantic segmentation. R.
Girshick et al. CVPR 2013 [pdf]
-
*Contextual Priming for Object Detection, A. Torralba. IJCV 2003. [pdf] [web] [code]
-
*A Discriminatively Trained, Multiscale, Deformable Part Model, by P. Felzenszwalb, D. McAllester and D. Ramanan. CVPR 2008. [pdf] [code]
Paper-Richard Teammco
Paper-Huihuang Zheng
Expt-Adam Allevato
Expt-William Xie
Visual properties, learning from natural language descriptions, intermediate shared representations

Image credit: Lampert et al.
-
Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer, C. Lampert, H. Nickisch, and S. Harmeling, CVPR 2009 [pdf] [web] [data]
-
Poselets: Body Part Detectors Trained Using 3D Human Pose Annotations. L. Bourdev and J. Malik. CVPR 2009. [pdf] [code] [web]
- Discovering the spatial extent of relative attributes. F. Xiao and Y. J. Lee. ICCV 2015. [pdf] [code]
- Animals with Attributes dataset
- aYahoo and aPascal attributes datasets
- Attribute discovery dataset of shopping categories
- Public Figures Face database with attributes
- Relative attributes data
- WhittleSearch relative attributes data
- SUN Scenes attribute dataset
- Cross-category object recognition (CORE) dataset
- Leeds Butterfly Dataset
- FaceTracer database from Columbia
- Caltech-UCSD Birds dataset
- Database of human attributes
- More attribute datasets
- 2014 Workshop on
Parts & Attributes
Paper-Akanksha Saran
Paper-Zhuode Liu
Expt-Aishwarya Padmakumar
Expt-Abhishek Sinha
Expt-Ashwini Venkatesh
Tuesday March 8, 11 am: Talk by Philipp Krahenbuhl, UC Berkeley. GDC Auditorium

Image credit: Antol et al.
- VQA: Visual Question Answering. Antol et al. ICCV 2015 [pdf][data/code/demo]
- Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing. Izadinia, Sadeghi, Divvala, Hajishirzi, Choi, Farhadi. ICCV 2015 [pdf]
- Ask Your Neurons: A Neural-Based Approach to
Answering Questions About Images. Malinowski,
Rohrbach, Fritz. ICCV 2015. [pdf]
[video]
[code/data]
Paper-Edward Banner
Paper-Surbhi Goel
Expt-Huihuang Zheng
Expt-Kunal Lad
Guest speaker: Subha Venugopalan
Tuesday March 22, 11 am: Talk by David Fouhey, CMU. GDC Auditorium
Feature learning, semantics learning. Leveraging free or nearly free cues for supervision. Internet data, video, egomotion, context...

Image credit: X. Chen et al.
- Learning image representations
equivariant to ego-motion. Jayaraman and
Grauman. ICCV 2015. [pdf]
[web]
[slides] [data]
- NEIL: Extracting Visual Knowledge from Web Data, Chen, Shrivastava, and Gupta, ICCV 2013 [pdf]
- Learning temporal embeddings for complex video analysis. Ramanathan, Tang, Mori, Fei-Fei. ICCV 2015 [pdf]
Paper-Chad Voegele
Paper-Bo Xiong
Expt-Ashish Bora
Expt-Ruohan Gao
Linking and visualizing multi-view data from tourist photos, image-based geolocalization, natural scene text detection, discovering correlated non-visual properties in street-side imagery

Image credit: T-Y. Lin et al.
- *Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition. Jaderberg, Simonyan, Vedaldi, Zisserman. NIPS Deep Learning Workshop, 2014. [pdf] [journal paper]
- *Learning Deep Representations for
Ground-to-Aerial Geolocalization. T. Lin, Y.
Cui, S. Belongie, and J. Hays. CVPR 2015.
[pdf]
[poster]
[slides]
- *City Forensics: Using VIsual Elements
to Predict Non-Visual City Attributes. Arietta,
Efros, Ramammoorthy, Agrawala. Trans on
Visualization and Graphics, 2014. [pdf]
[web]
Paper-Kunal Lad
Expt-Zhuode Liu
Expt-Ruohan Zhang
Expt-Richard Teammco
3d structure (single views, panoramas, RGBD) and scene layout for visual recognition
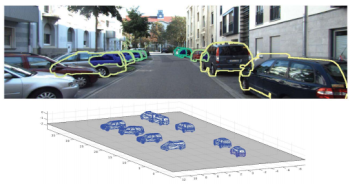
Image credit: Y. Xiang et al.
- PanoContext: A Whole-room 3D Context
Model for Panoramic Scene Understanding. Y.
Zhang, S. Song, P. Tan, J. Xiao. ECCV
2014. [pdf]
[data/code]
[slides]
- Data-Driven 3D Voxel Patterns for
Object Category Recognition, Y. Xiang, W. Choi, Y. Lin
and S. Savarese, CVPR
2015. [pdf]
[web/data]
[slides]
- Indoor
Segmentation and Support Inference
from RGBD Images.
N. Silberman, D. Hoiem, P.
Kohli, and R. Fergus. ECCV
2012. [pdf]
[code/data]
[NYU
depth dataset] [slides]
Paper-William Xie
Expt-Hilgad Montelo
Expt-Chun-Chen Kuo
Expt-Andrew Sharp
Learning how to move for recognition, manipulation. 3D objects and the next best view.

Image credit: Malmir et al.
- Deep Q-learning for active recognition
of GERMS: Baseline performance on a standardized
dataset for active learning. Malmir et al. BMVC
2015. [pdf]
[data]
- Active Object Recognition using Vocabulary Trees. N Govender, J. Claassens, P. Torr, J. Warrell. Workshop on Robot Vision, 2013. [pdf]
Paper-Ruohan Zhang
Paper-Abhishek Sinha
Expt-Manu Agarwal
Expt-Yinan Zhao
Predicting what gets noticed or remembered in images and video. Saliency, importance, memorability, photography biases.

Image credit: T. Liu et al.
- Understanding and Predicting Image Memorability at a Large Scale. A. Khosla, S. Raju, A. Torralba, and A. Oliva. ICCV 2015. [pdf] [web] [code/data]
- Learning video saliency from human
gaze using candidate selection. D. Rudoy et al.
CVPR 2013 [pdf]
[web]
[video]
[code]
- MIT saliency benchmark
- Saliency
datasets
- The DIEM Project: visualizing dynamic images and eye movements
- MIT eye tracking data
- LaMem Demo
- LaMem Dataset
- MSRA salient object database
- MED video summaries dataset
- ETHZ video summaries dataset
- VSUMM dataset for video summarization
- UT Egocentric dataset / important regions
- VideoSET summary evaluation data
- Salient Montages dataset
Paper-Ashish Bora
Expt-Bo Xiong
Expt-Akanksha Saran
Expt-Tyler Folkman
Cues from people in images: body pose, social groups and roles, attention, gaze following, scene structure

Image credit: Khosla et al.
- People Watching: Human Actions as a
Cue for Single View Geometry. Fouhey, Delaitre,
Gupta, Efros, Laptev, Sivic. ECCV 2012 [pdf]
[journal]
[web]
[slides]
[video]
Paper-Ashwini Venkatesh
Expt-Surbhi Goel
Expt-Edward Banner
See Piazza post for details